Hi,
I got a multi-class segmentation model running from end-to-end but it seems to be performing incorrectly. I did some debugging and I believe it is because the DataLoader is incorrectly reading in the masks.
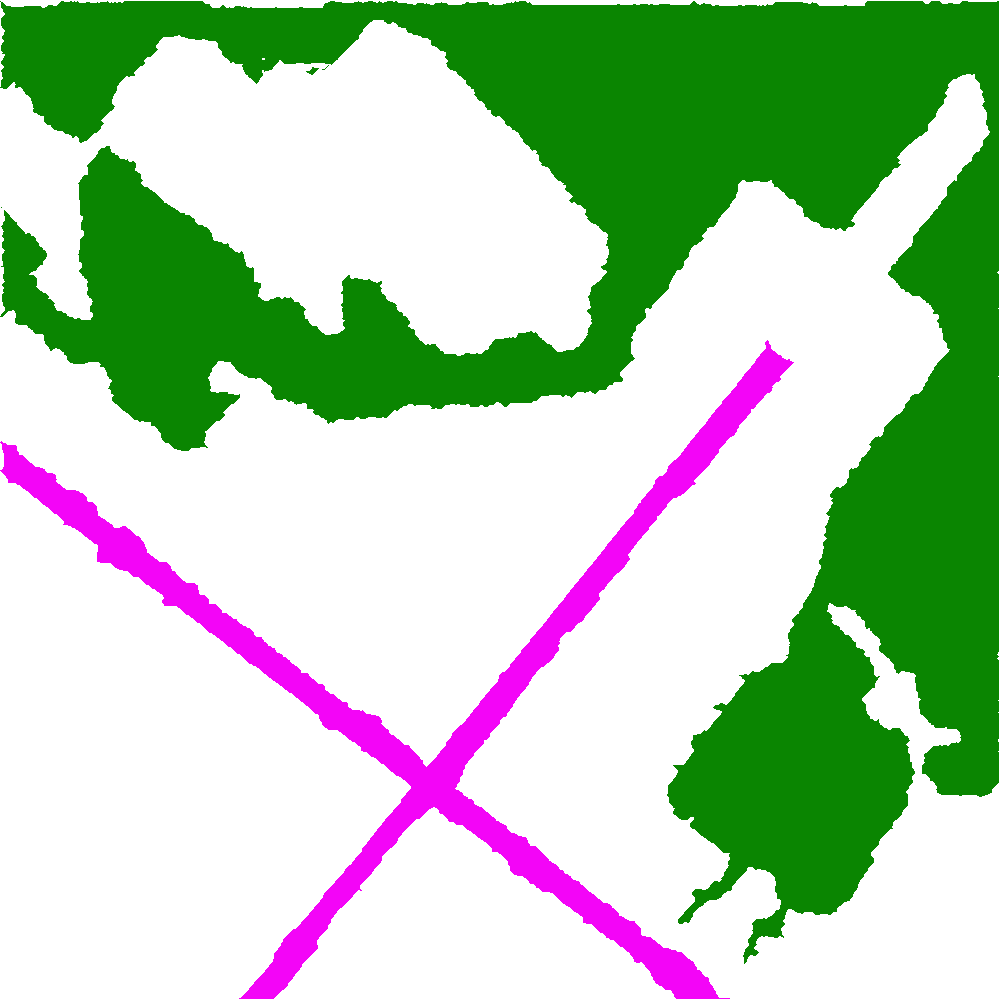
For example, here is a mask with 3 classes:
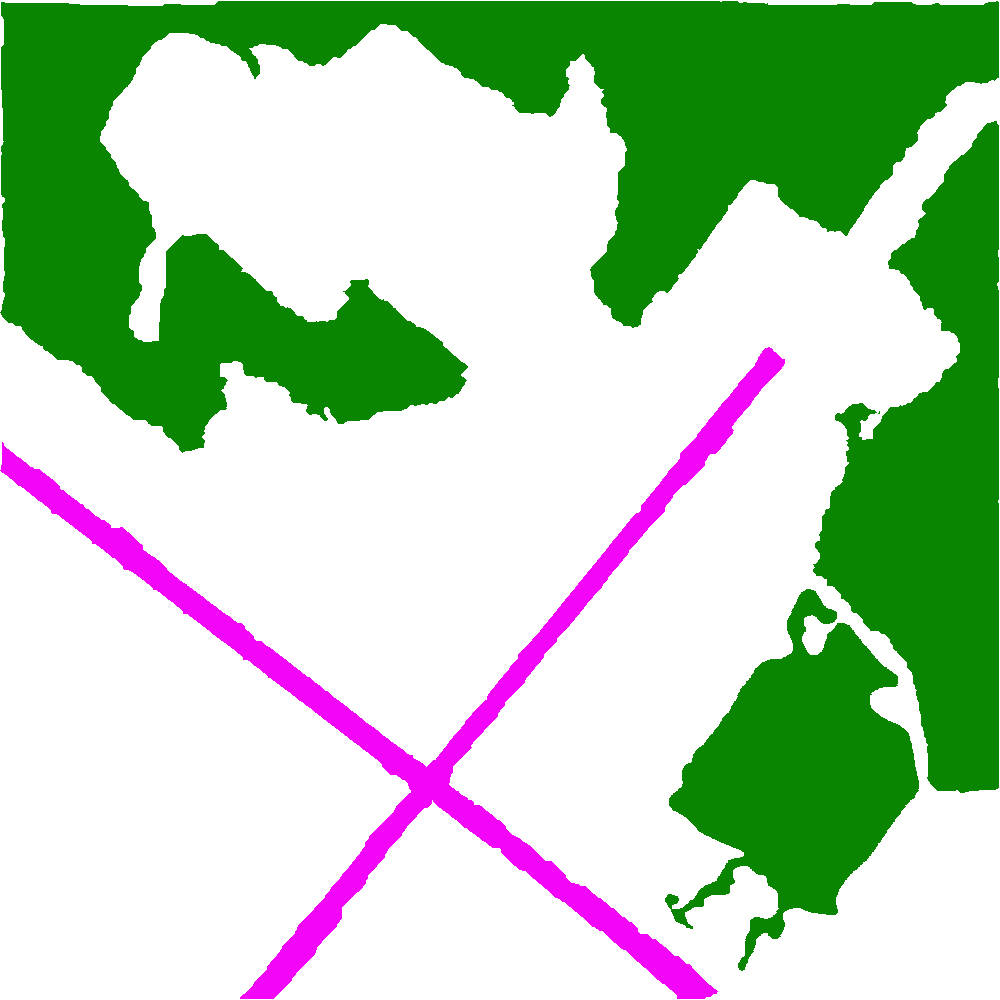
And here is how the DataLoader perceives this mask. It gets read in as black and white and it seems that only one class is preserved (we no longer see a pink X on the bottom).

This is how getitem is defined for my DataLoader:
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.images[index])
mask_path = os.path.join(self.mask_dir, self.images[index].replace(".jpg", "_mask.png"))
image = np.array(Image.open(img_path).convert("RGB"), dtype=np.float32)
mask = np.array(Image.open(mask_path).convert("RGB"), dtype=np.float32)
target = torch.from_numpy(mask)
h,w = target.shape[0], target.shape[1]
mask = torch.empty(h, w, dtype = torch.long)
colors = torch.unique(target.view(-1, target.size(2)), dim=0).numpy()
target = target.permute(2, 0, 1).contiguous()
mapping = {tuple(c): t for c, t in zip(colors.tolist(), range(len(colors)))}
for k in mapping:
# Get all indices for current class
idx = (target==torch.tensor(k, dtype=torch.uint8).unsqueeze(1).unsqueeze(2))
validx = (idx.sum(0) == 3) # Check that all channels match
mask[validx] = torch.tensor(mapping[k], dtype=torch.long)
if self.transform is not None:
mask = mask.numpy()
augmentations = self.transform(image=image, mask=mask)
image = augmentations["image"]
mask = augmentations["mask"]
print(f"image shape: {image.shape}\n")
print(f"mask shape: {mask.shape}\n")
torchvision.utils.save_image(image, "data/inside_data_loader/" + self.images[index])
torchvision.utils.save_image(mask.float(), "data/inside_data_loader/" + self.images[index].replace(".jpg", "_mask.png"))
return image, mask
As we see, we simply input the image and corresponding mask and then retrieve the colors from the mask and create a color map. Then before returning I save the image and corresponding mask so that way I can have an idea of how the DataLoader views them.
As for the transformations, I simply normalize and convert to a tensor as follows:
train_transform = A.Compose(
[
#A.Resize(height=IMAGE_HEIGHT, width=IMAGE_WIDTH),
#A.Rotate(limit=35, p=1.0),
#A.HorizontalFlip(p=0.5),
#A.VerticalFlip(p=0.1),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
val_transforms = A.Compose(
[
#A.Resize(height=IMAGE_HEIGHT, width=IMAGE_WIDTH),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
Any idea why my model is perceiving my mask this way? Is this behavior correct?
Thank you very much!