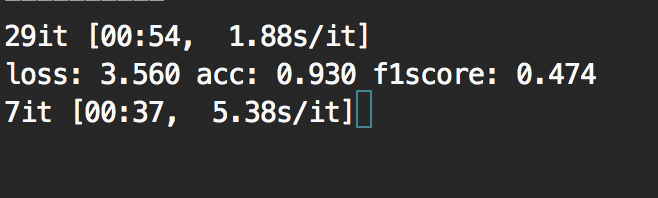
My dataloader does not seem consistent in speed performance. My data is saved in .h5 formats such as as dataset_sub1.h5, dataset_sub2.h5 … I am using tqdm to show progress. When loading dataset_sub1.h5, it takes 1.88s/it, (1 it corresponds to 200 samples). But for the next file dataset_sub2.h5, it is much slower with 5.38s/it. (The batch size is the same)
I am using single GPU Tesla P40.
I have tried several times, results show that the speed is not consistent, please see the screenshot below.
My questions are:
What is causing the variation, data loading or GPU computation?
How to fix the issue?
Class definition
Class data_hdf5(Dataset):
def __init__(self, hdf5_path, transform=None):
hdf5_file = h5py.File(hdf5_path, mode='r')
self.hdf5_file = hdf5_file
self.transform = transform
def __len__(self):
return self.hdf5_file['filenames'].size
def __getitem__(self, idx):
gray = self.hdf5_file['images'][idx]
image = color.gray2rgb(gray)
filename = self.hdf5_file['filenames'][idx]
if self.transform:
image = self.transform(image)
image = image.type(torch.FloatTensor)
else:
image = torch.from_numpy( gray ).type(torch.FloatTensor)
label = torch.from_numpy( self.hdf5_file['labels'][idx] ).type(torch.FloatTensor)
sample = {'image': image, 'label':label}
return sample
main script using dataloader
set_dict = {‘train’: list(range(1,4)))}
hdf5_path = [ ‘data/dataset_sub’+str(i)+‘.h5’ for i in range(1,4) ]
datasets = [ data_hdf5(tmp, transform=data_transforms) for tmp in hdf5_path ]
dataloaders = [ torch.utils.data.DataLoader(tmp, batch_size=batch_size, shuffle=True, num_workers=1, pin_memory=False) for tmp in datasets ] # a list of dataloaders, each loads a dataset_sub*.h5 file.