Hello everyone!
I try to rebuild the following paper work with the KITTI-Dataset.
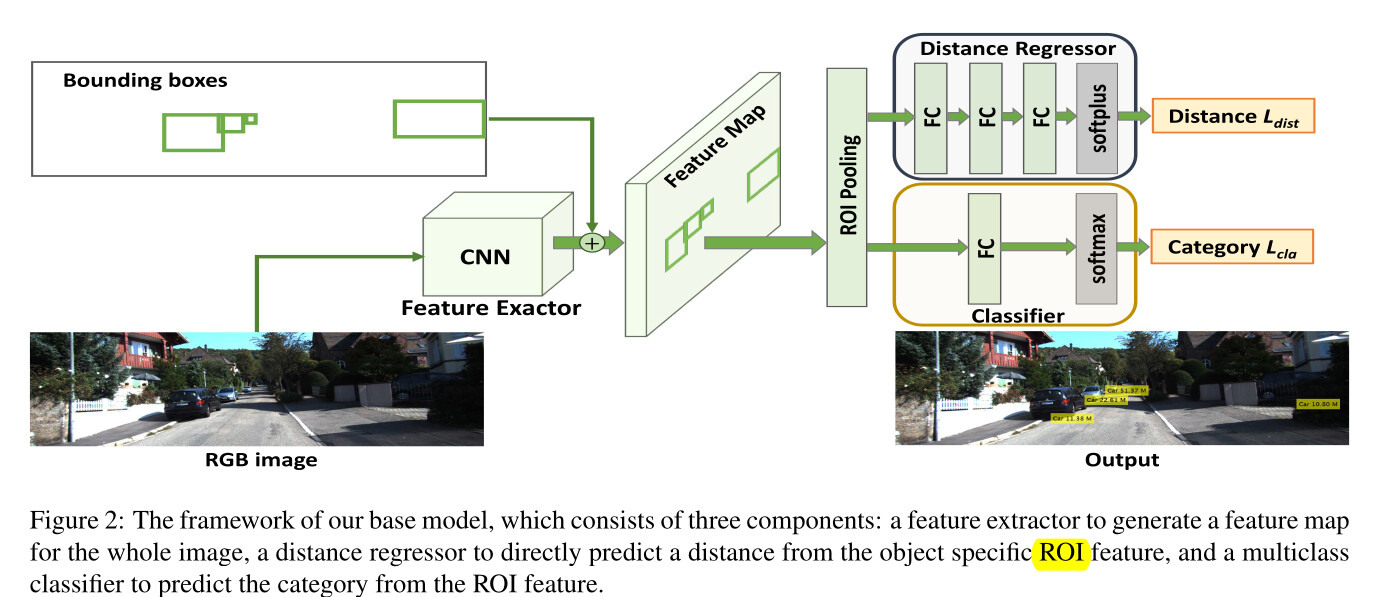
Source | Paper
Unfortunately I have no clue how to pass the different features to the DataLoader and recall them by the different steps (image*, bounding boxes for ROI Polling, types/classes, and additional features of the KITTI_Dataset) and of course the labels: distance (which is already concated in my textfiles).
*Image is the “main feature” from where the Features should be extracted by the FeactureExtractor.
My CustomDataset-Class looks like this right now:
import csv
import os
import pandas as pd
from typing import Any, Callable, List, Optional, Tuple
from PIL import Image
from torchvision.datasets.vision import VisionDataset
# df_dict = {'type': 0, 'truncated': 1, 'occluded': 2, 'alpha': 3, 'bbox': 4, 'dimensions': 5, 'location': 6, 'rotation_y': 7, 'forward_distance': 8, 'forward_keypoint': 9}
# df_types_dict = {'Car': 0, 'Van': 1, 'Truck': 2,'Pedestrian': 3, 'Person_sitting': 4, 'Cyclist': 5, 'Tram': 6, 'Misc': 7, 'DontCare': 8}
class KittiDist(VisionDataset):
"""KittiDist-Class for `KittiDist`_Dataset.
It corresponds to the "left color images of object" dataset, for object detection.
Args:
root (string): Root directory where images are downloaded to.
Expects the following folder structure if download=False:
.. code::
<root>
└── KittiDist --> During Test: "TEST_SET"
├── images
└── distLabels
develop (bool, optional): If true, another File-Path is used. Could be used if
during development another (smaller, special selected) Dataset-Folder is needed.
train (bool, optional): Use ``train`` split if true, else ``test`` split.
Defaults to ``train``.
transform (callable, optional): A function/transform that takes in a PIL image
and returns a transformed version. E.g, ``transforms.PILToTensor``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
transforms (callable, optional): A function/transform that takes input sample
and its target as entry and returns a transformed version.
"""
# Dataset
# Numbers of images: 007480.png (last image)
image_dir_name = "images"
labels_dir_name = "distLabel"
main_dir_name = "KITTI-Dist"
develop_dir_name = "TEST_SET"
# Set DevMode (Small Dataset), else whole Dataset
# develop: bool = True
def __init__(
self,
root: str,
develop: bool = False,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
transforms: Optional[Callable] = None,
):
super().__init__(
root,
transform=transform,
target_transform=target_transform,
transforms=transforms,
)
self.images = [] # A list of all images
self.targets = [] # A list of all Anno-Files (distLabel), xy.targets = [idx] will return a certain path.
self.root = root
self.train = train
self.develop = develop
self._location = self.develop_dir_name if self.develop else self.main_dir_name
image_dir = os.path.join(self.root, self._location, self.image_dir_name)
if self.train:
labels_dir = os.path.join(self.root, self._location, self.labels_dir_name)
# For every single Image in the path "image_dir" will be appended the Ref. to the "image"-List.
for img_file in os.listdir(image_dir):
self.images.append(os.path.join(image_dir, img_file))
if self.train:
self.targets.append(os.path.join(labels_dir, f"{img_file.split('.')[0]}.txt"))
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""Get item at a given index.
Args:
index (int): Index
Returns:
tuple: (image, target), where
target is a list of dictionaries with the following keys:
- type: str
- truncated: float
- occluded: int
- alpha: float
- bbox: float[4]
- dimensions: float[3]
- locations: float[3]
- rotation_y: float
- forward_distance: float
- forward_keypoint: float[2]
"""
image = Image.open(self.images[index])
target = self._parse_target(index) if self.train else None
if self.transforms:
image, target = self.transforms(image, target)
return image, target
def _parse_target(self, index: int) -> List:
target = []
with open(self.targets[index]) as inp:
content = csv.reader(inp, delimiter=" ")
for line in content:
target.append(
{
"type": line[0],
"truncated": float(line[1]),
"occluded": int(line[2]),
"alpha": float(line[3]),
"bbox": [float(x) for x in line[4:8]],
"dimensions": [float(x) for x in line[8:11]],
"location": [float(x) for x in line[11:14]],
"rotation_y": float(line[14]),
## Add distance and coordinates for the LIDAR-Point to which the computed distance belongs
"forward_distance": float(line[15]),
## This should be 16:18; [18] because the last number ends on [17]. Compair with location, which ends with [13].
"forward_keypoint": [float(x) for x in line[16:18]],
}
)
return target
def __len__(self) -> int:
return len(self.images)
The “TEST_SET” is just another folder, with less images during development.
Additionally my resize/augmentation function, which is not implemented into the DatasetClass:
import albumentations
import cv2
import numpy as np
def resize_img_bb_kyp(img_arr, bboxes, keypoints, height, width, flip_prob):
"""
:param img_arr: original image as a numpy array
:param bboxes: bboxes as numpy array where each row is 'x_min', 'y_min', 'x_max', 'y_max'.
:param h: resized height dimension of image
:param w: resized weight dimension of image
:param keypoints: keypoints as numpy array, each row is 'x' 'y'
:return: dictionary containing {image:transformed (flipped?), bboxes_transformed:['x_min', 'y_min', 'x_max', 'y_max', "keypoints_transformed]}
Adapted from: https://sheldonsebastian94.medium.com/resizing-image-and-bounding-boxes-for-object-detection-7b9d9463125a
"""
# resize transform pipeline
transform_img_bb_kyp = albumentations.Compose(
[albumentations.Resize(height=height, width=width, always_apply=True),
albumentations.HorizontalFlip(p=flip_prob)],
bbox_params=albumentations.BboxParams(format='pascal_voc', label_fields=[]),
keypoint_params=albumentations.KeypointParams(format="xy"))
transformed_img_bb_kyp = transform_img_bb_kyp(image=img_arr, bboxes=bboxes, keypoints=keypoints)
return transformed_img_bb_kyp
So as an overwiew:
main feature: image – for CNN feature extractor
feature: BoundingBoxes – for ROI pooling
feature: Keypoints (maye used later)
feature: type (object classes) – not sure; if I really use it, since I want to use a classifier
label: distance
I have one big folder with all the images; another folder for the Textfiles (which containts the features, and the label).
So I struggle with the following questions:
- How to pass the several features and the label (distance) to the DataLoader?
- How does the DataLoader look like?
- How do I access the different features after handing it to the DataLoader?
- Is there a smooth way, how to integrate my resize/augmentation-function into the Dataset-Class, or do I have to use pytrochs Transform? ( I am using my own resize function, since pyTorchs Transform doesnt transform the coordinates of the BoundingBoxes, and keypoints.
I would really appreciate any help.
– Thanks and enjoy your day.
P.S. This issue didn’t really helped me …