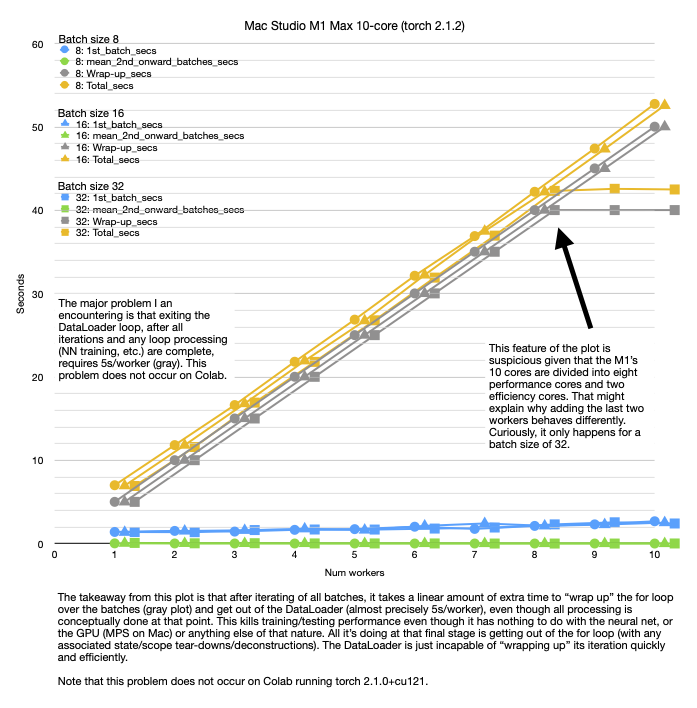
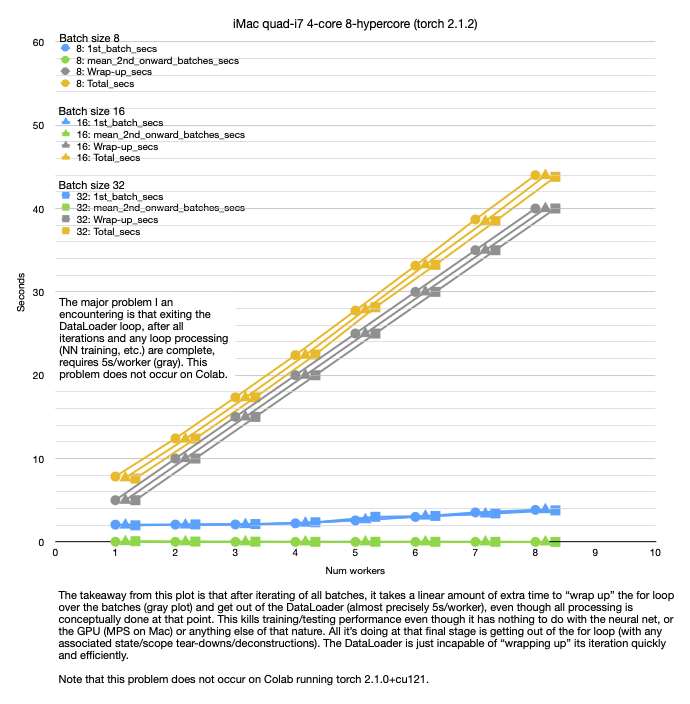
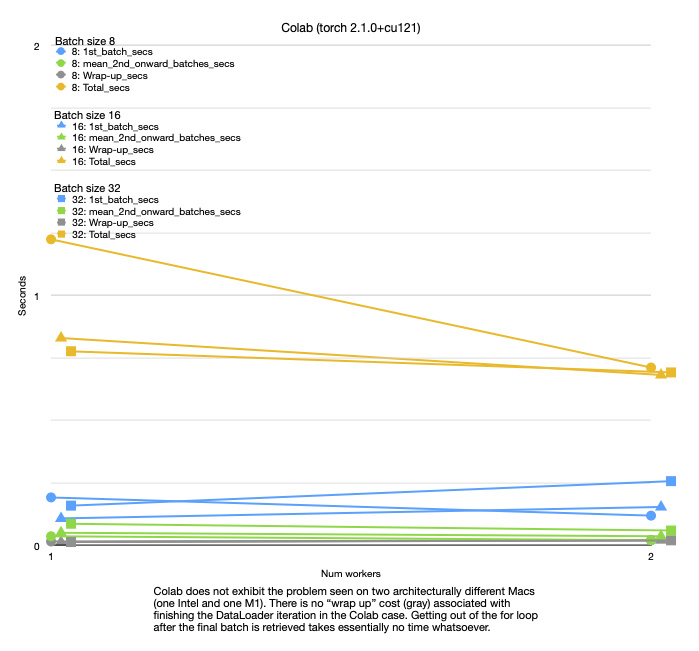
On two very different Mac architectures (i7 and M1), both running torch 2.1.2, I’m seeing a 5s/worker delay in wrapping up a DataLoader batch loop (which costs 40-50s per epoch of completely wasted time). But on Colab, running torch 2.1.0+cu121, I don’t see this effect.
This absolutely kills training/testing because it can add 5s/worker to each epoch for both the training loop and the testing loop. That is time that has nothing to do with the GPU (MPS on Mac), nothing even to do with NN training at all. And it also isn’t time spent actually loading data from disk. That went quickly during the iteration over the DataLoader. This problem occurs after the entire iteration is complete and the for loop is just trying to “get out”. It sits there for a huge amount of time, presumably deconstructing some massive amount of state – but it doesn’t do that on Colab. This makes PyTorch all but useless on the Mac. 5-epoch trainings that take 10s on Colab end up taking over 200s on both Macs. I don’t know if the problem is the slight difference in torch version or something to do with the Mac. It has nothing to do with the recent MPS Metal GPU support though, since I am getting the same result on an i7 Intel iMac (plus the code clearly makes no use of the MPS).
See attached plots.
Any ideas?
Here’s sample output from a single experiment, just to show what the output looks like:
Batch size: 32 Num workers: 10
Creating DataLoader with batch size 32 and 10 workers.
Iterating over DataLoader
Batch 1 time: 3.01242
Batch 2 time: 0.00620
Batch 3 time: 0.00006
Batch 4 time: 0.00003
Batch 5 time: 0.00003
Batch 6 time: 0.00005
Batch 7 time: 0.00005
Batch 8 time: 0.00004
Enumeration wrap-up time: 40.02002
Total time: 43.03889
The code to reproduce the experiments is below. It uses a dataset from a popular Udemy course.
import os
from timeit import default_timer
from pathlib import Path
import pandas as pd
import numpy as np
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
def download_data(image_path):
if image_path.is_dir():
print(f"{image_path} directory exists.")
else:
print(f"Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
# 16.2 MB dataset comprising 225 and 75 train/test images
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:
request = requests.get("https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip")
print("Downloading pizza, steak, sushi data...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zip_ref:
print("Unzipping pizza, steak, sushi data...")
zip_ref.extractall(image_path)
# data_path = Path("data/")
image_path = data_path / "pizza_steak_sushi"
train_dir = image_path / "train"
download_data(image_path)
# Create simple transform
simple_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
])
# Load and transform data
from torchvision import datasets
train_data_simple = datasets.ImageFolder(root=train_dir, transform=simple_transform)
# Setup batch size and number of workers
BATCH_SIZE = 32
NUM_WORKERS = os.cpu_count()
rows = []
for batch_size in [8, 16, 32]:
for num_workers in range(1, NUM_WORKERS + 1):
print("_" * 100)
print(f"Batch size: {batch_size:>2} Num workers: {num_workers:>2}")
# Create DataLoader
print(f"Creating DataLoader with batch size {batch_size} and {num_workers} workers.")
train_dataloader_simple = DataLoader(train_data_simple,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers)
# Iterate over the batch without doing anything with the images
print("Iterating over DataLoader")
times = [default_timer()]
for batch, (X, y) in enumerate(train_dataloader_simple):
times.append(default_timer())
# print(f"Batch {batch + 1}")
times.append(default_timer())
print()
for ti, t in enumerate(times):
if ti > 0:
et = t - times[ti - 1]
if ti < len(times) - 1:
print(f"Batch {ti:>2} time: {et:9.5f}")
else:
print(f"Enumeration wrap-up time: {et:9.5f}")
et = times[-1] - times[0]
print(f"Total time: {et:9.5f}")
mean_batch_time_wo_first_batch = np.mean([times[i] - times[i-1] for i in range(2, len(times)-1)])
row = [batch_size, num_workers, times[1] - times[0], mean_batch_time_wo_first_batch, times[-1] - times[-2], times[-1] - times[0]]
rows.append(row)
df = pd.DataFrame(rows, columns=["Batch_size", "Num_workers", "1st_batch_secs", "mean_2nd_onward_batches_secs", "Wrap-up_secs", "Total_secs"])
display(df)
print()