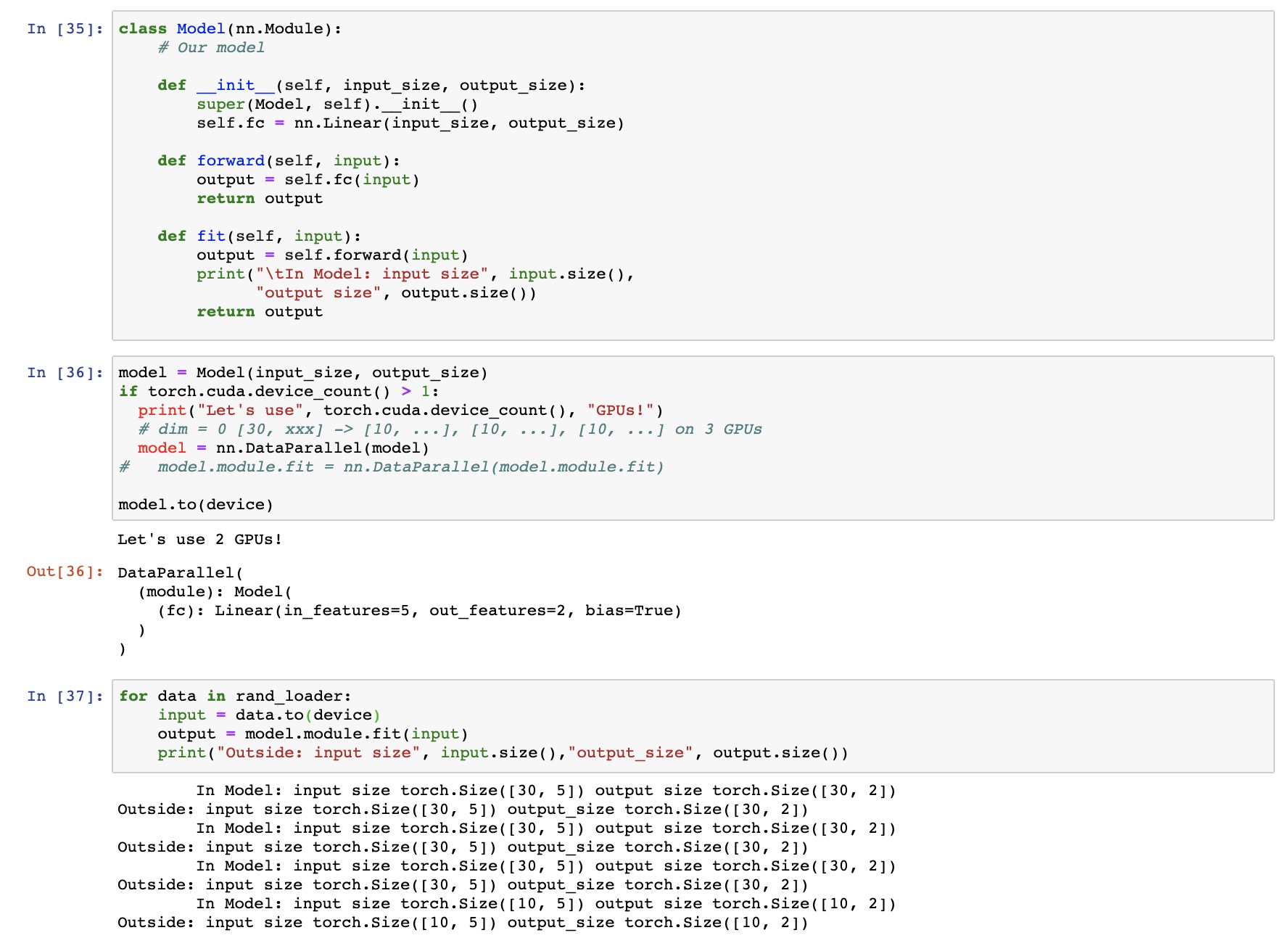
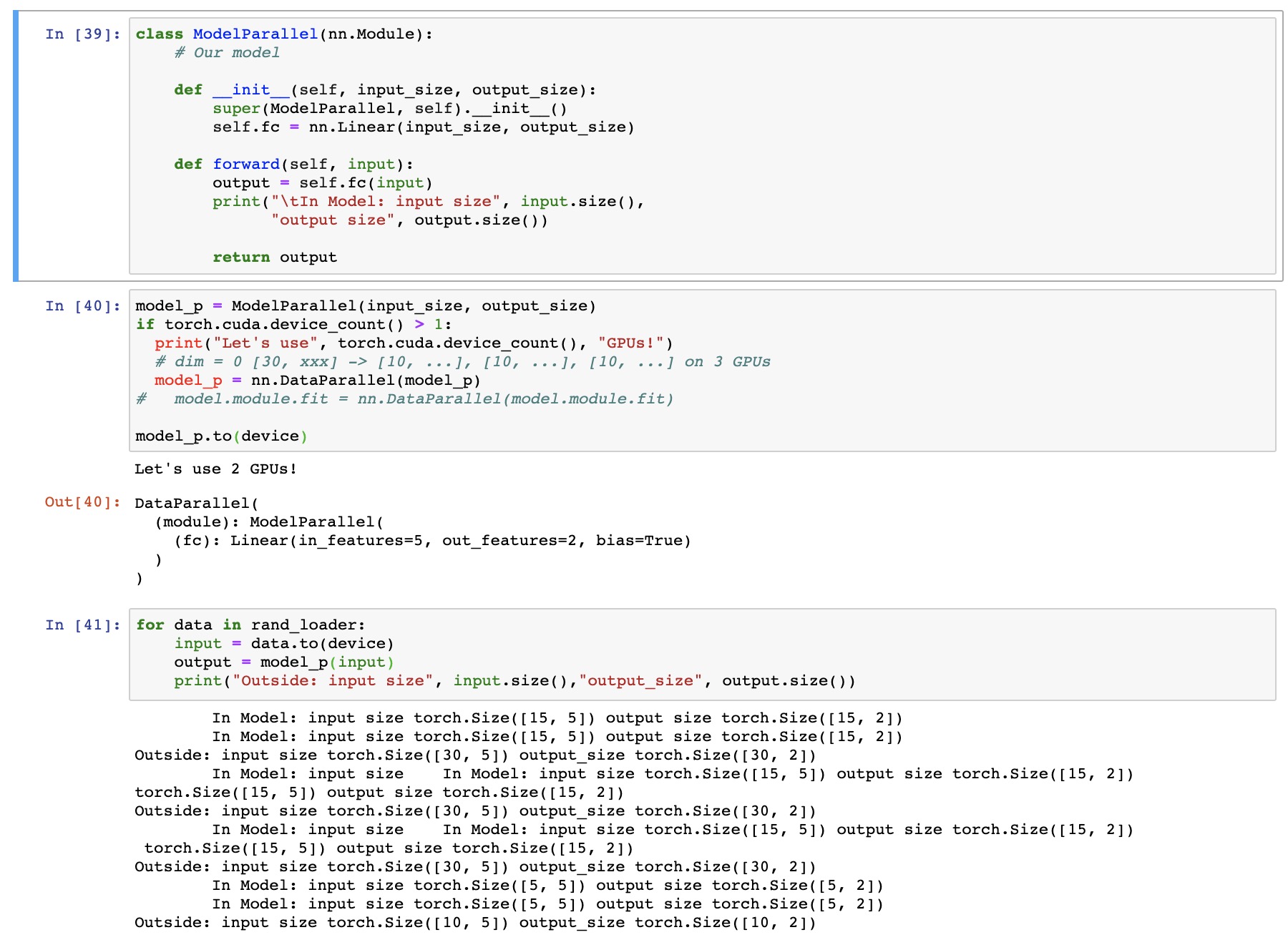
So in the two images there are two different models
model and model_p both being wrapped under nn.DataParallel. But in model when calling some attribute fit using the model.module method, I’m unable utilize the two GPUs I originally wanted to parallelize my model upon. i.e model doesn’t split the dim=0 batch_first dimension into two equal halves for putting it onto two devices as can be seen from the print statements.Ps. I am very new to using DataParallel and wanted to use something like this. i.e What I actually want is, to call
model.module.fit in my training loop with the args as the inputs from my dataloader and in this fit attribute ultimately will makes a call to the forward method of the class model.
But this whole thing doesn’t seem to parallelize and utilize the two GPUs which the model_p could without any fit function and a direct call to forward internally.
I’ve added the link to the notebook which was run with CUDA_VISIBLE_DEVICES=0,1
What should I change?
Thanks!
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
return output
def fit(self, input):
output = self.forward(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
for data in rand_loader:
input = data.to(device)
output = model.module.fit(input)
print("Outside: input size", input.size(),"output_size", output.size())
#############################CASE 2############################
class ModelParallel(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(ModelParallel, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
model_p = ModelParallel(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model_p = nn.DataParallel(model_p)
# model.module.fit = nn.DataParallel(model.module.fit)
model_p.to(device)
for data in rand_loader:
input = data.to(device)
output = model_p(input)
print("Outside: input size", input.size(),"output_size", output.size())
