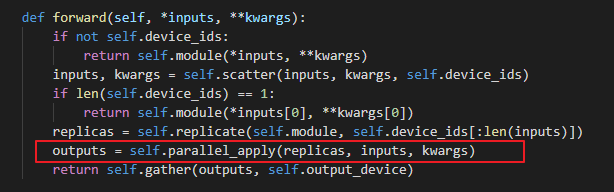
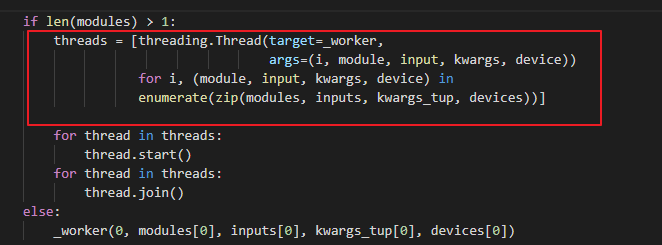
I guess it will depend on the size of the net you are using.
If it is very small, then your will spend most time executing python code and thus using threading will slow you down.
Otherwise, most of the time will be spent running stuff on the GPU anyway and so there is no use for multiple processes. In that case threads are used as they are much cheaper to create.