tuotuoZ
April 21, 2019, 4:33am
1
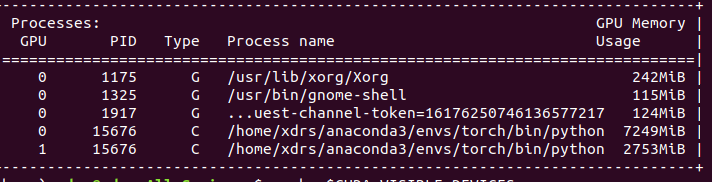
Hi all, I am using two RTX 2080 right now and I am trying to fit a large model. When I use the dataparallel command it seemed utilizing the first CUDA device more than the second. Then it gave me the error CUDA out of memory. I check the nvidia-smi info:
Is there something wrong with my code so it’s only using the first CUDA device memory more? Thanks in advance
tuotuoZ
April 21, 2019, 4:36am
2
Here is my code. I am using a 150 x 150 RGB images to train the model. The current batch size is 64.
import torch.nn as nn
import torch.nn.functional as F
# define the CNN architecture from this kaggle example https://www.kaggle.com/uzairrj/beg-tut-intel-image-classification-93-76-accur
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# convolutional layer (sees 150x150x3 image tensor)112,56,28
self.conv1 = nn.Conv2d(3, 200, 3)
self.conv1 = nn.DataParallel(self.conv1)
# convolutional layer (sees 16x16x16 tensor)
self.conv2 = nn.Conv2d(200, 180, 3)
self.conv2 = nn.DataParallel(self.conv2)
# convolutional layer (sees 8x8x32 tensor)
self.conv3 = nn.Conv2d(180, 180, 3)
self.conv3 = nn.DataParallel(self.conv3)
self.conv4 = nn.Conv2d(180, 140, 3)
self.conv4 = nn.DataParallel(self.conv4)
self.conv5 = nn.Conv2d(140, 100, 3)
self.conv5 = nn.DataParallel(self.conv5)
self.conv6 = nn.Conv2d(100, 50, 3)
self.conv6 = nn.DataParallel(self.conv6)
# max pooling layer
self.pool = nn.MaxPool2d(5, 5)
# linear layer (7 * 7 * 128 -> 1024)
self.fc1 = nn.Linear(800, 180)
# linear layer (500 -> 10)
self.fc2 = nn.Linear(180, 100)
self.fc3 = nn.Linear(100, 50)
self.fc4 = nn.Linear(50, 6)
# dropout layer (p=0.5)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = self.pool(F.relu(self.conv6(x)))
# flatten image input
x = x.view(-1, 800)
# add dropout layer
# add 1st hidden layer, with relu activation function
x = F.relu(self.fc1(x))
# add 2nd hidden layer, with relu activation function
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
# add dropout layer
x = self.dropout(x)
x = self.fc4(x)
return x
# create a complete CNN
model = Net()
print(model)
# move tensors to GPU if CUDA is available
model.to('cuda')
import torch.optim as optim
# specify loss function (categorical cross-entropy)
criterion = nn.CrossEntropyLoss()
# specify optimizernnnn
optimizer = optim.Adam(model.parameters(), lr=1e-4)
As I wrote in the other thread.
Don’t add nn.DataParallel inside your model class class Net(nn.Module)
Use the following pattern:
# create model
model = Net()
# move to GPU
model = model.cuda()
# split up input batch to all GPUs
model = nn.DataParallel(model)
tuotuoZ
April 21, 2019, 5:29pm
4
Thanks for pointing that out. I was reading this example thread about DataParallel Maybe someone should this a little bit?