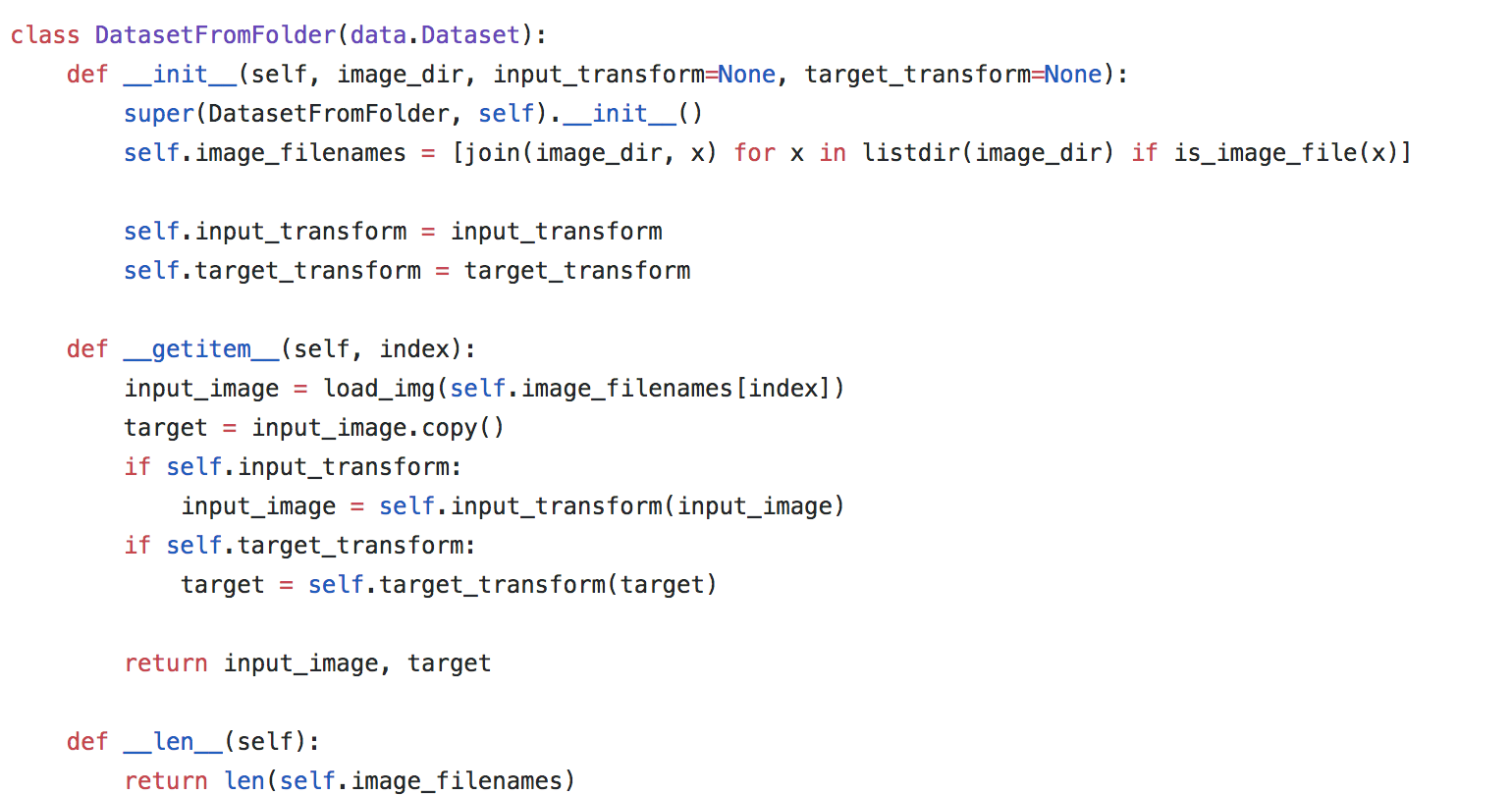
NOW, i am writing a super-resolution code.but i am confused about the dataset implementation,
if i only have a directory about my training image, i can write the code like the above image,
but, if i have an input image folder,and a target(gronud truth)image folder,what should i edit it?
def init(self,input_img_dir,target_img_dir,…):
self.input_img_files=[os.list.]
self.target_img_files=[os.list]
sort()
sort()
def __getitem(item,index):
#so,the index is the input_img index or target_img index?and how to get right training image pairs?
Hi,
To train with pairs of images you have to generate couple of corresponding lists, such that list1[idx] finds its analogous sample in list2[idx].
Dataloader is data agnostic. At the time of shuffling, it only shuffles a list of indices, which initially is ordered.
I will appreciate it if you are so kind to write the code like the above picture.
The code is data-dependent so I cannot really write it.
In fact it does not appear how do you load target images.
It should be something like:
class dataset():
def init()
self.images_list = load the list...
self.target_list = load the list....
def __len__:
return len(self.images_list) which should be the same as target list
def __getitem__(self,idx):
input_image = loadimg(self.images_list[idx])
target_image = loadimg(self.target_list[idx])
The idx should point to corresponding pairs of img/ground-truth. However this does not depend on pytorch framework but your code in init function. You have to make them match somehow
I see, thank you very much