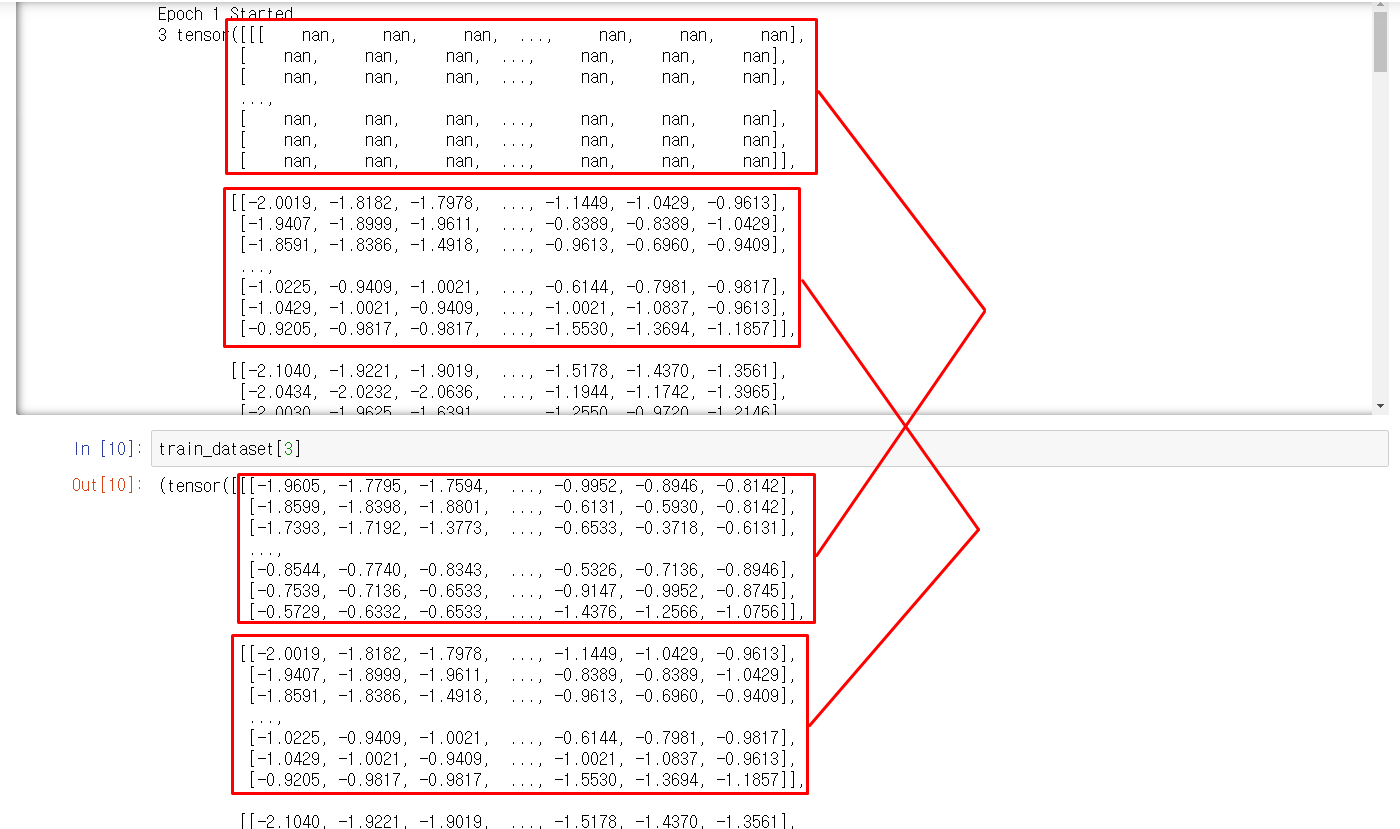
As you replied I tried and it worked!
If I set pin_memory=False, it works just fine 
I share my experiment with ur suggestions as follows (u can see more details with codes)
- Experiment 1 - torch.cuda.synchronize() - not worked
- Experiment 2 - non_blocking=False - not worked
- Experiment 3 - pin_memory=False - worked
Also I share my env for reproduction (for info, I used official pytorch docker image pytorch/pytorch:1.8.1-cuda11.1-cudnn8-devel and just install jupyter notebook using pip)
And just curious that I’m sharing 1 GPU with other users cause of lack of GPUs, is this matter..??
# env
!python -m torch.utils.collect_env
# result
Collecting environment information...
PyTorch version: 1.8.1
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Python version: 3.8 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: A100-SXM4-40GB
GPU 1: A100-SXM4-40GB
GPU 2: A100-SXM4-40GB
GPU 3: A100-SXM4-40GB
GPU 4: A100-SXM4-40GB
GPU 5: A100-SXM4-40GB
GPU 6: A100-SXM4-40GB
GPU 7: A100-SXM4-40GB
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.19.2
[pip3] torch==1.8.1
[pip3] torchelastic==0.2.2
[pip3] torchtext==0.9.1
[pip3] torchvision==0.9.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.1.74 h6bb024c_0 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2020.2 256
[conda] mkl-service 2.3.0 py38he904b0f_0
[conda] mkl_fft 1.3.0 py38h54f3939_0
[conda] mkl_random 1.1.1 py38h0573a6f_0
[conda] numpy 1.19.2 py38h54aff64_0
[conda] numpy-base 1.19.2 py38hfa32c7d_0
[conda] pytorch 1.8.1 py3.8_cuda11.1_cudnn8.0.5_0 pytorch
[conda] torchelastic 0.2.2 pypi_0 pypi
[conda] torchtext 0.9.1 py38 pytorch
[conda] torchvision 0.9.1 py38_cu111 pytorch
Experiment 1. Insert torch.cuda.synchronize() - didn’t work
- I tried the experiments as below (adding more torch.cuda.synchronize())
# Default Dataset, Dataloader codes for Experiment 1
batch_size = 128
train_transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.4921, 0.4828, 0.4474], std=[0.1950, 0.1922, 0.1940])])
test_transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.4921, 0.4828, 0.4474], std=[0.1950, 0.1922, 0.1940])])
train_dataset = torchvision.datasets.CIFAR10('./cifar10/', train=True, download=True, transform=train_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=False, pin_memory=True)
test_dataset = torchvision.datasets.CIFAR10('./cifar10/', train=False, download=True, transform=test_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, pin_memory=True)
Experiment 1-1
# train code - 1
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=True), y.cuda(self.gpu, non_blocking=True)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(True, device='cuda:1')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-16c095588069> in <module>
----> 1 WRN_28_10.train(train_loader, test_loader, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
/workspace/jaeseong_lee/WideResNet/train.py in train(self, train_data, test_data, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
46
47 optimizer.zero_grad()
---> 48 loss.backward()
49 optimizer.step()
50
/opt/conda/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
247 def register_hook(self, hook):
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
143 retain_graph = create_graph
144
--> 145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: Function 'LogSoftmaxBackward' returned nan values in its 0th output.
Experiment 1-2
# train code - 2
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=True), y.cuda(self.gpu, non_blocking=True)
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(True, device='cuda:1')
tensor(True, device='cuda:1')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-16c095588069> in <module>
----> 1 WRN_28_10.train(train_loader, test_loader, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
/workspace/jaeseong_lee/WideResNet/train.py in train(self, train_data, test_data, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
46
47 optimizer.zero_grad()
---> 48 loss.backward()
49 optimizer.step()
50
/opt/conda/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
247 def register_hook(self, hook):
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
143 retain_graph = create_graph
144
--> 145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: Function 'LogSoftmaxBackward' returned nan values in its 0th output.
Experiment 1-3
# train code - 3
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
torch.cuda.synchronize(self.gpu)
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=True), y.cuda(self.gpu, non_blocking=True)
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(True, device='cuda:1')
tensor(True, device='cuda:1')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-16c095588069> in <module>
----> 1 WRN_28_10.train(train_loader, test_loader, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
/workspace/jaeseong_lee/WideResNet/train.py in train(self, train_data, test_data, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
46
47 optimizer.zero_grad()
---> 48 loss.backward()
49 optimizer.step()
50
/opt/conda/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
247 def register_hook(self, hook):
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
143 retain_graph = create_graph
144
--> 145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: Function 'LogSoftmaxBackward' returned nan values in its 0th output.
Experiment 1-4
# train code - 4
torch.cuda.synchronize(self.gpu)
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
torch.cuda.synchronize(self.gpu)
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=True), y.cuda(self.gpu, non_blocking=True)
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(True, device='cuda:1')
tensor(True, device='cuda:1')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-16c095588069> in <module>
----> 1 WRN_28_10.train(train_loader, test_loader, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
/workspace/jaeseong_lee/WideResNet/train.py in train(self, train_data, test_data, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
46
47 optimizer.zero_grad()
---> 48 loss.backward()
49 optimizer.step()
50
/opt/conda/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
247 def register_hook(self, hook):
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
143 retain_graph = create_graph
144
--> 145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: Function 'LogSoftmaxBackward' returned nan values in its 0th output.
Experiment 2. Set non_blocking=False - didn’t work
# Default Dataset, Dataloader codes for Experiment 2
batch_size = 128
train_transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.4921, 0.4828, 0.4474], std=[0.1950, 0.1922, 0.1940])])
test_transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.4921, 0.4828, 0.4474], std=[0.1950, 0.1922, 0.1940])])
train_dataset = torchvision.datasets.CIFAR10('./cifar10/', train=True, download=True, transform=train_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=False, pin_memory=True)
test_dataset = torchvision.datasets.CIFAR10('./cifar10/', train=False, download=True, transform=test_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, pin_memory=True)
Experiment 2-1 (without inserting torch.cuda.synchronize())
# train code - 1
#torch.cuda.synchronize(self.gpu)
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
#torch.cuda.synchronize(self.gpu)
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
#torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=False), y.cuda(self.gpu, non_blocking=False)
print(X.isnan().any())
#torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(True, device='cuda:1')
tensor(True, device='cuda:1')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-16c095588069> in <module>
----> 1 WRN_28_10.train(train_loader, test_loader, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
/workspace/jaeseong_lee/WideResNet/train.py in train(self, train_data, test_data, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
46
47 optimizer.zero_grad()
---> 48 loss.backward()
49 optimizer.step()
50
/opt/conda/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
247 def register_hook(self, hook):
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
143 retain_graph = create_graph
144
--> 145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: Function 'LogSoftmaxBackward' returned nan values in its 0th output.
Experiment 2-2 (inserting torch.cuda.synchronize() as Experiment 1-4)
# train code - 2
torch.cuda.synchronize(self.gpu)
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
torch.cuda.synchronize(self.gpu)
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=False), y.cuda(self.gpu, non_blocking=False)
print(X.isnan().any())
torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(True, device='cuda:1')
tensor(True, device='cuda:1')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-16c095588069> in <module>
----> 1 WRN_28_10.train(train_loader, test_loader, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
/workspace/jaeseong_lee/WideResNet/train.py in train(self, train_data, test_data, save, epochs, lr, momentum, weight_decay, nesterov, milestones)
46
47 optimizer.zero_grad()
---> 48 loss.backward()
49 optimizer.step()
50
/opt/conda/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
247 def register_hook(self, hook):
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
143 retain_graph = create_graph
144
--> 145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: Function 'LogSoftmaxBackward' returned nan values in its 0th output.
Experiment 3. pin memory=False - works well
Experiment 3-1 (without torch.cuda.synchronize(), non_blocking=True)
# Dataset, Dataloader codes
batch_size = 128
train_transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.4921, 0.4828, 0.4474], std=[0.1950, 0.1922, 0.1940])])
test_transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.4921, 0.4828, 0.4474], std=[0.1950, 0.1922, 0.1940])])
train_dataset = torchvision.datasets.CIFAR10('./cifar10/', train=True, download=True, transform=train_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=False, pin_memory=False)
test_dataset = torchvision.datasets.CIFAR10('./cifar10/', train=False, download=True, transform=test_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, pin_memory=False)
# train code - 1
#torch.cuda.synchronize(self.gpu)
for epoch in range(epochs):
if epoch % self.epoch_print == 0: print('Epoch {} Started...'.format(epoch+1))
#torch.cuda.synchronize(self.gpu)
for i, (X, y) in enumerate(train_data):
print(X.isnan().any())
#torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
X, y = X.cuda(self.gpu, non_blocking=True), y.cuda(self.gpu, non_blocking=True)
print(X.isnan().any())
#torch.cuda.synchronize(self.gpu)
print(X.isnan().any())
# result
Epoch 1 Started...
tensor(False)
tensor(False)
tensor(False, device='cuda:1')
tensor(False, device='cuda:1')
tensor(False)
tensor(False)
tensor(False, device='cuda:1')
tensor(False, device='cuda:1')
tensor(False)
tensor(False)
tensor(False, device='cuda:1')
tensor(False, device='cuda:1')
tensor(False)
tensor(False)
tensor(False, device='cuda:1')
tensor(False, device='cuda:1')