I’ve been building a DCGAN following the PyTorch tutorial with some modifications.
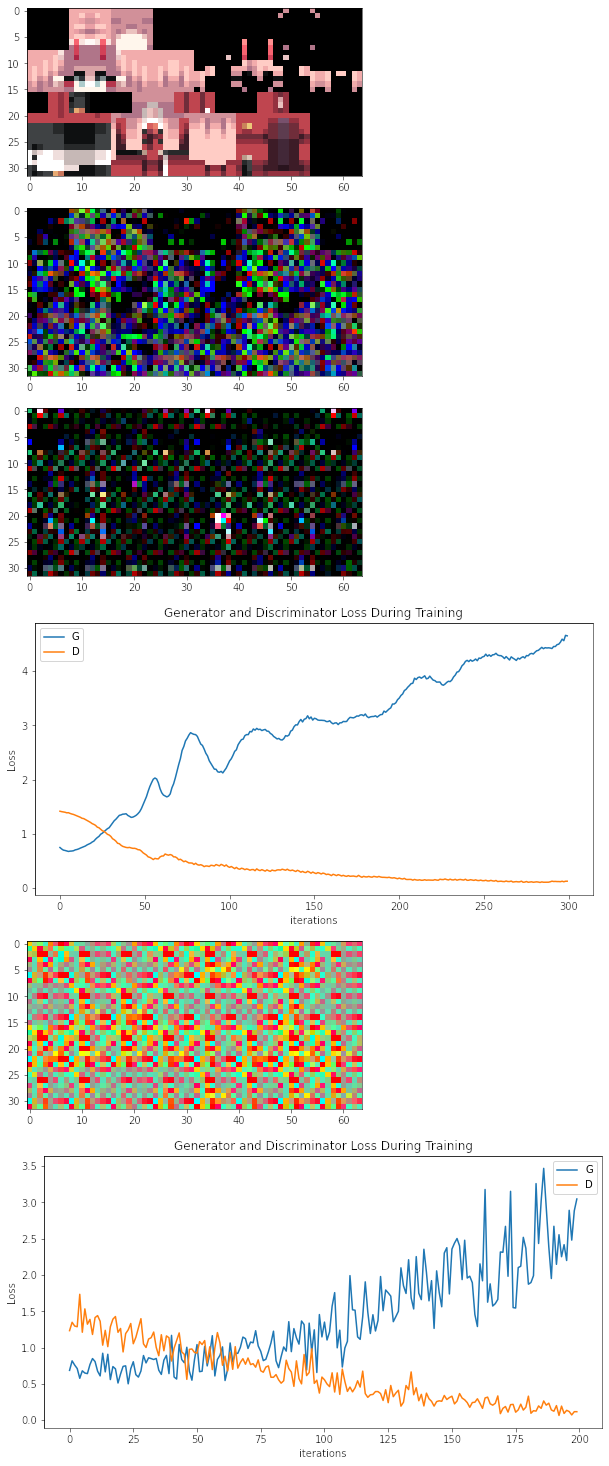
The data I’m training with is Minecraft skins that I scraped from the internet. The images’ dimensions are 64x32x3. See the first image below for an example. (Sorry about having to combine all the images into one. As a new user of the forum, I can only include one image in my post.)
No matter what I do, after the first few epochs of training, the generator seems to keep generating images with weird patterns. See the second image below for an example.
As I continue training, it seems to trend towards making the whole image black except for a few pixels. See the third image below. This effect becomes even more pronounced as I train the model for longer. The fourth image below shows the generator and discriminator losses as training progresses.
I also tried training it on only one image, expecting it to over fit and always generate the same picture, so I could see if the model was working correctly. Surprisingly, the model seems to continue to output garbage. The image I used to train is the first image below. See the fifth image below for an example of a generated image and the sixth image for a graph of the losses.
In all cases, the generator’s loss appears to continuously increase as the discriminator’s loss decreases. This leads me to believe that the generator isn’t training properly. I think I have an error somewhere either in my training loop or in the generator’s architecture. I’ve checked both multiple times, but I can’t seem to find any errors. I couldn’t seem to find any information on using ConvTranspose2d to create rectangular images, and I may have introduced an error when I tried to figure out how to do it myself. Any help would be appreciated.
Here is the code for the models:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.conv_transpose_1 = nn.ConvTranspose2d(50, 64, 4, 4)
self.batch_norm_1 = nn.BatchNorm2d(64)
self.conv_transpose_2 = nn.ConvTranspose2d(64, 32, 2, 2)
self.batch_norm_2 = nn.BatchNorm2d(32)
self.conv_transpose_3 = nn.ConvTranspose2d(32, 16, 2, 2)
self.batch_norm_3 = nn.BatchNorm2d(16)
self.conv_transpose_4 = nn.ConvTranspose2d(16, 8, 2, 2)
self.batch_norm_4 = nn.BatchNorm2d(8)
self.conv_transpose_5 = nn.ConvTranspose2d(8, 3, 1, 1)
def forward(self, x):
x = x.view(-1, 50, 1, 2)
x = self.conv_transpose_1(x)
x = self.batch_norm_1(x)
x = F.relu(x)
x = self.conv_transpose_2(x)
x = self.batch_norm_2(x)
x = F.relu(x)
x = self.conv_transpose_3(x)
x = self.batch_norm_3(x)
x = F.relu(x)
x = self.conv_transpose_4(x)
x = self.batch_norm_4(x)
x = F.relu(x)
x = self.conv_transpose_5(x)
x = (F.hardtanh(x) + 1) / 2
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv_1 = nn.Conv2d(3, 64, 4, 2)
self.dropout_1 = nn.Dropout()
self.conv_2 = nn.Conv2d(64, 128, 2, 2)
self.batch_norm_1 = nn.BatchNorm2d(128)
self.dropout_2 = nn.Dropout()
self.conv_3 = nn.Conv2d(128, 64, 2, 2)
self.batch_norm_2 = nn.BatchNorm2d(64)
self.dropout_3 = nn.Dropout()
self.linear_1 = nn.Linear(64 * 3 * 7, 128)
self.linear_2 = nn.Linear(128, 1)
def forward(self, x):
x = self.conv_1(x)
x = F.leaky_relu(x, 0.2)
x = self.dropout_1(x)
x = self.conv_2(x)
x = self.batch_norm_1(x)
x = F.leaky_relu(x, 0.2)
x = self.dropout_2(x)
x = self.conv_3(x)
x = self.batch_norm_2(x)
x = F.leaky_relu(x, 0.2)
x = self.dropout_3(x)
x = self.linear_1(x.view(x.shape[0], -1))
x = F.leaky_relu(x, 0.2)
x = self.linear_2(x)
x = torch.sigmoid(x)
return x
Here’s the code for the training loop:
discriminator = Discriminator().to('cuda')
generator = Generator().to('cuda')
criterion = nn.BCELoss()
optimizerDiscriminator = optim.Adam(discriminator.parameters(), lr=0.0001)
optimizerGenerator = optim.Adam(generator.parameters(), lr=0.01)
d_loss = []
g_loss = []
for epoch in range(NUM_EPOCHS):
for i, (images, _) in enumerate(loader, 0):
batch_size = images.size(0)
# Train discriminator
discriminator.zero_grad()
# Train the discriminator with real images
labels = torch.full((batch_size,), REAL_LABEL, dtype=torch.float).to('cuda')
output = discriminator(images.to('cuda')).view(-1)
err = criterion(output, labels)
err.backward()
d_loss.append(err)
print(err)
# Train the discriminator with generated images
labels = torch.full((batch_size,), FAKE_LABEL, dtype=torch.float).to('cuda')
noise = torch.randn(batch_size, 100).to('cuda')
with torch.no_grad():
fake_images = generator(noise)
output = discriminator(fake_images.detach()).view(-1)
err = criterion(output, labels)
err.backward()
d_loss[-1] += err
print(err)
optimizerDiscriminator.step()
# Train generator
generator.zero_grad()
labels = torch.full((batch_size,), REAL_LABEL, dtype=torch.float).to('cuda')
noise = torch.randn(batch_size, 100).to('cuda')
fake_images = generator(noise)
output = discriminator(fake_images).view(-1)
err = criterion(output, labels)
err.backward()
g_loss.append(err)
print(err)
optimizerGenerator.step()
print()
print(epoch)