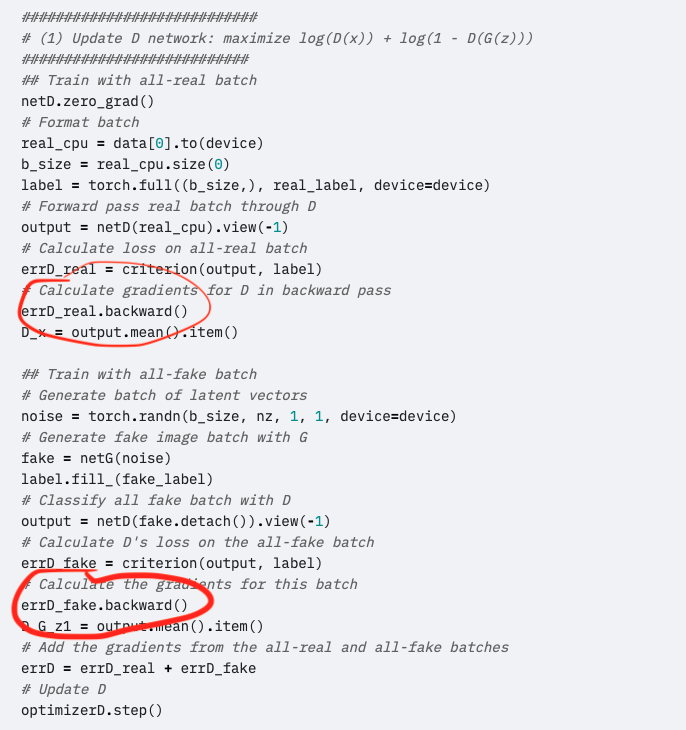
I think it’s a tradeoff between time and GPU memory.
For the memory: With the setup in the code, you can produce and process the autograd graphs for real and fake separately, so in a very lame sense, you can “double the batch size”.
In terms of performance: In the end, yes, without memory constraints, you would probably go for doing both at the same time (but also for the forward!). However, the advantage of “processing more data in one go” levels off at some point, so it might less general when you manage to efficiently use the GPU with the current setup, you have little to gain by doing real and fake in one go. (Basically just from the gradient accumulation itself, not so much the intermediates in the backward pass.)
Now, if you run on multi-GPU, the scaling probably works in favor of the backward once approach you suggest, at least if you also parallelize the forward passes.
In the end, the situation seems complicated enough that with the right batch size, I’d expect the sequential setup to be competitive in terms of speed. But it’s not optimization until you measure it, so it’d be interesting to hear about your experience.
So with “my” setup you would basically call 2-times forward before you call backward(), and since backward clears the graph, you have a larger graph in the background in my case. I fact, now I think that both approaches I listed above may be equivalent (depending on how autograd is implemented) in terms of the number of operations performed by backward. In that case, the approach in the tutorial is probably preferred because you have a smaller graph, keeping memory consumption lower.
Btw when I benchmarked both approaches, both approaches had similar speed. But yeah, it’s a relatively small network and image size.