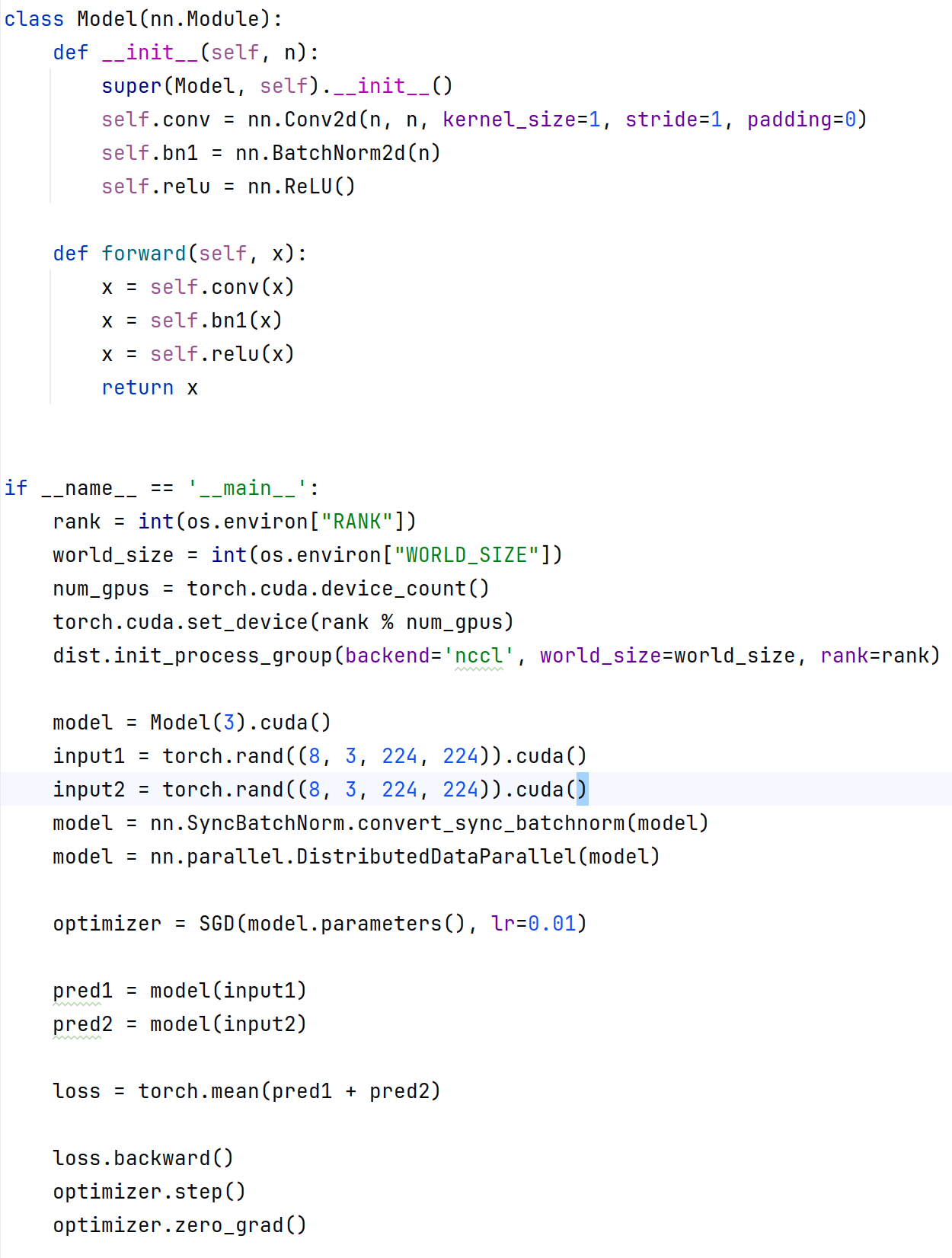
When using DDP, if there is a batch normalization (BN) layer in the network and only a single GPU is employed, an error will occur after two consecutive forward passes prior to backward propagation:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
However, this issue does not arise when using multiple GPUs. Why is this the case,?nn.SyncBatchNorm.convert_sync_batchnorm() has already been applied to convert batch normalization to synchronized batch normalization.
I would assume DDP would detect a single GPU and would execute the single GPU run. However, I also don’t understand your use case in applying DDP on a single device.
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [3]] is at version 3; expected version 2 instead.
If I run CUDA_VISIBLE_DEVICES=2,3 torchrun --nproc_per_node 2 train.py, there is no error.