here is my test code as follows, it seems no errors
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1, 2,3,4"
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", init_method='tcp://127.0.0.1:6666', rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
print("finished rank: {}".format(rank))
def main():
world_size = torch.cuda.device_count()
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
but the result is very strange, as we can see, the card 0 occupied more space
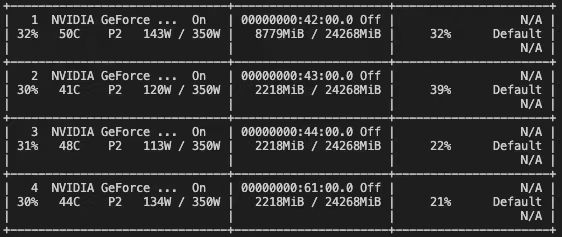
I don’t know where the error occurred