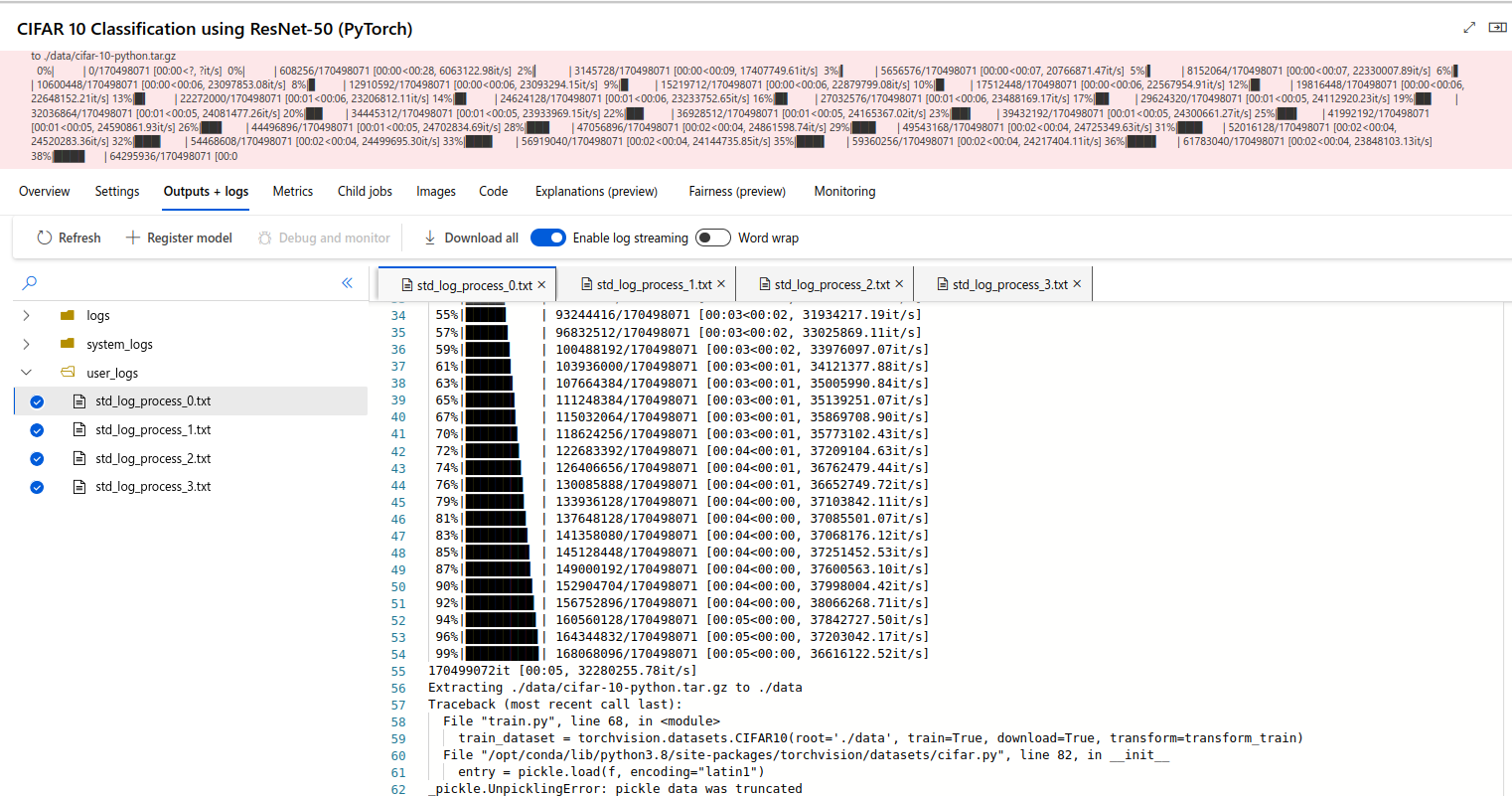
Can you please take a look at this DDP code and let me know what is wrong? The non-DDP code runs correctly on single GPU. I am using Azure Cluster with 4 nodes each with 4 GPUs so total of 16 GPUs.
4 processes failed. Please see below for their details:
Execution failed. User process 'Rank 8' exited with status code 1. Please check log file 'user_logs/std_log_process_08.txt' for error details. Error: Traceback (most recent call last):
File "train.py", line 68, in <module>
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
File "/opt/conda/lib/python3.8/site-packages/torchvision/datasets/cifar.py", line 65, in __init__
self.download()
File "/opt/conda/lib/python3.8/site-packages/torchvision/datasets/cifar.py", line 141, in download
download_and_extract_archive(self.url, self.root, filename=self.filename, md5=self.tgz_md5)
File "/opt/conda/lib/python3.8/site-packages/torchvision/datasets/utils.py", line 430, in download_and_extract_archive
download_url(url, download_root, filename, md5)
File "/opt/conda/lib/python3.8/site-packages/torchvision/datasets/utils.py", line 152, in download_url
raise RuntimeError("File not found or corrupted.")
RuntimeError: File not found or corrupted.
Execution failed. User process 'Rank 9' killed by signal with name SIGKILL. It was terminated by the runtime due to failure in other processes on the same node. Please check log file 'user_logs/std_log_process_09.txt' for error details.
Execution failed. User process 'Rank 10' killed by signal with name SIGKILL. It was terminated by the runtime due to failure in other processes on the same node. Please check log file 'user_logs/std_log_process_10.txt' for error details.
Execution failed. User process 'Rank 11' killed by signal with name SIGKILL. It was terminated by the runtime due to failure in other processes on the same node. Please check log file 'user_logs/std_log_process_11.txt' for error details.
code:
import time
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import mlflow
import os
import datetime
import configparser
import logging
import argparse
from PIL import Image
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
start_time = time.time()
# Set the seed for reproducibility
torch.manual_seed(42)
# Set up the data loading parameters
batch_size = 128
num_epochs = 2
num_workers = 4
pin_memory = True
# Get the world size and rank to determine the process group
world_size = int(os.environ['WORLD_SIZE'])
world_rank = int(os.environ['RANK'])
local_rank = int(os.environ['LOCAL_RANK'])
is_distributed = world_size > 1
if is_distributed:
batch_size = batch_size // world_size
batch_size = max(batch_size, 1)
# Set the backend to NCCL for distributed training
dist.init_process_group(backend="nccl",
init_method="env://",
world_size=world_size,
rank=world_rank)
# Set the device to the current local rank
device = torch.device('cuda', local_rank)
# Define the transforms for the dataset
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
])
# Load the CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, num_replicas=world_size, rank=world_rank)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=(train_sampler is None), num_workers=num_workers, pin_memory=pin_memory, sampler=train_sampler)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=pin_memory)
# Define the ResNet50 model
model = torchvision.models.resnet50(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 10)
# Move the model to the GPU
model = model.to(device)
# Wrap the model with DistributedDataParallel
if is_distributed:
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Train the model for the specified number of epochs
for epoch in range(num_epochs):
running_loss = 0.0
train_sampler.set_epoch(epoch) ### why is this line necessary??
for batch_idx, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('[Epoch %d] loss: %.3f' % (epoch + 1, running_loss))
# Log the loss and running loss as MLFlow metrics
mlflow.log_metric("loss", loss.item())
mlflow.log_metric("running loss", running_loss)
# Save the trained model
if world_rank == 0:
checkpoints_path = "train_checkpoints"
os.makedirs(checkpoints_path, exist_ok=True)
torch.save(model.module.state_dict(), '{}/{}-{}.pth'.format(checkpoints_path, 'resnet50_cifar10', world_rank))
mlflow.log_artifact('{}/{}-{}.pth'.format(checkpoints_path, 'resnet50_cifar10', world_rank), artifact_path="model_state_dict")
# Evaluate the model on the test set and save inference on 6 random images
correct = 0
total = 0
with torch.no_grad():
fig, axs = plt.subplots(2, 3, figsize=(8, 6), dpi=100)
axs = axs.flatten()
count = 0
for data in test_loader:
if count == 6:
break
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# Save the inference on the 6 random images
if count < 6:
image = np.transpose(inputs[0].cpu().numpy(), (1, 2, 0))
confidence = torch.softmax(outputs, dim=1)[0][predicted[0]].cpu().numpy()
class_name = test_dataset.classes[predicted[0]]
axs[count].imshow(image)
axs[count].set_title(f'Class: {class_name}\nConfidence: {confidence:.2f}')
axs[count].axis('off')
count += 1
# Average the test accuracy across all processes
torch.distributed.all_reduce(correct, op=torch.distributed.ReduceOp.SUM)
torch.distributed.all_reduce(total, op=torch.distributed.ReduceOp.SUM)
test_accuracy = 100 * correct / total
test_accuracy /= world_size
print('Test accuracy: %.2f %%' % test_accuracy)
# Save the plot with the 6 random images and their predicted classes and prediction confidence
plt.savefig('test_images.png')
# Log the test accuracy and elapsed time to MLflow
mlflow.log_metric("test accuracy", test_accuracy)
end_time = time.time()
elapsed_time = end_time - start_time
print('Elapsed time: ', elapsed_time)
mlflow.log_metric("elapsed time", elapsed_time)
# Save the plot with the 6 random images and their predicted classes and prediction confidence as an artifact in MLflow
image = Image.open('test_images.png')
image = image.convert('RGBA')
image_buffer = np.array(image)
image_buffer = image_buffer[:, :, [2, 1, 0, 3]]
image_buffer = np.ascontiguousarray(image_buffer)
mlflow.log_image(image_buffer, artifact_file="inference_on_test_images.png")
# End the MLflow run
if mlflow.active_run():
mlflow.end_run()
dist.destroy_process_group()