Hi there.
I am playing with ImageNet training in Pytorch following official examples. To log things in DDP training, I write a function get_logger:
import logging
import os
import sys
class NoOp:
def __getattr__(self, *args):
def no_op(*args, **kwargs):
"""Accept every signature by doing non-operation."""
pass
return no_op
def get_logger(log_dir, log_name=None, resume="", is_rank0=True):
"""Get the program logger.
Args:
log_dir (str): The directory to save the log file.
log_name (str, optional): The log filename. If None, it will use the main
filename with ``.log`` extension. Default is None.
resume (str): If False, open the log file in writing and reading mode.
Else, open the log file in appending and reading mode; Default is "".
is_rank0 (boolean): If True, create the normal logger; If False, create the null
logger, which is useful in DDP training. Default is True.
"""
if is_rank0:
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
# StreamHandler
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(level=logging.INFO)
logger.addHandler(stream_handler)
# FileHandler
mode = "w+" if resume == "False" else "a+"
if log_name is None:
log_name = os.path.basename(sys.argv[0]).split(".")[0] + (".log")
file_handler = logging.FileHandler(os.path.join(log_dir, log_name), mode=mode)
file_handler.setLevel(level=logging.INFO)
logger.addHandler(file_handler)
else:
logger = NoOp()
return logger
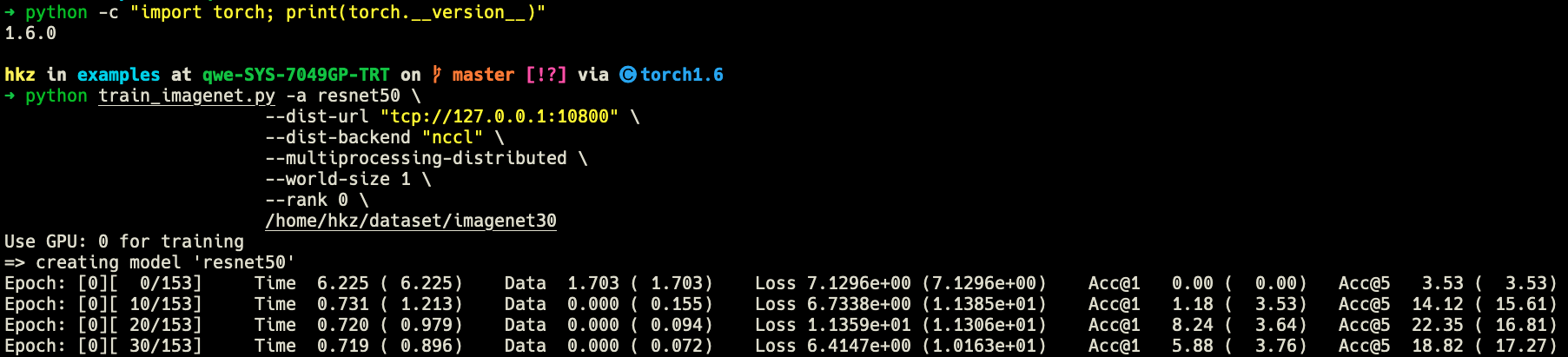
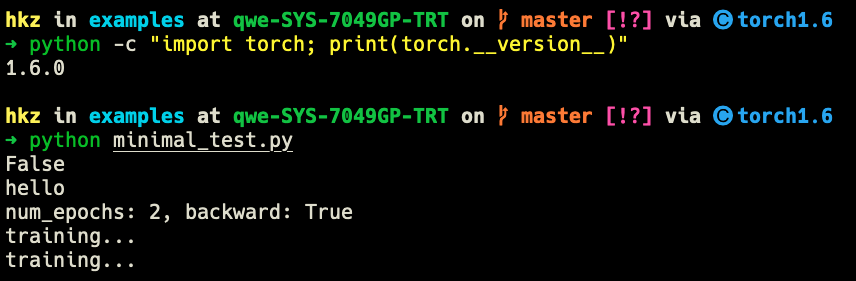
The logger should log to a file and print to stdout only in rank0. This works with torch.__version__<=1.6.0:
Use GPU: 0 for training
=> creating model 'resnet50'
Epoch: [0][ 0/153] Time 3.652 ( 3.652) Data 1.754 ( 1.754) Loss 7.1175e+00 (7.1175e+00) Acc@1 0.00 ( 0.00) Acc@5 0.00 ( 0.00)
Epoch: [0][ 10/153] Time 0.339 ( 0.632) Data 0.000 ( 0.160) Loss 8.2664e+00 (1.3576e+01) Acc@1 2.35 ( 2.67) Acc@5 11.76 ( 15.29)
Epoch: [0][ 20/153] Time 0.340 ( 0.493) Data 0.000 ( 0.089) Loss 5.9911e+00 (1.0709e+01) Acc@1 10.59 ( 3.75) Acc@5 21.18 ( 17.03)
Epoch: [0][ 30/153] Time 0.343 ( 0.444) Data 0.000 ( 0.064) Loss 4.9582e+00 (9.2672e+00) Acc@1 0.00 ( 3.49) Acc@5 16.47 ( 16.96)
Epoch: [0][ 40/153] Time 0.340 ( 0.419) Data 0.000 ( 0.051) Loss 4.5358e+00 (8.3598e+00) Acc@1 5.88 ( 3.64) Acc@5 15.29 ( 16.96)
Epoch: [0][ 50/153] Time 0.342 ( 0.404) Data 0.000 ( 0.043) Loss 3.4166e+00 (7.5119e+00) Acc@1 7.06 ( 3.62) Acc@5 22.35 ( 17.02)
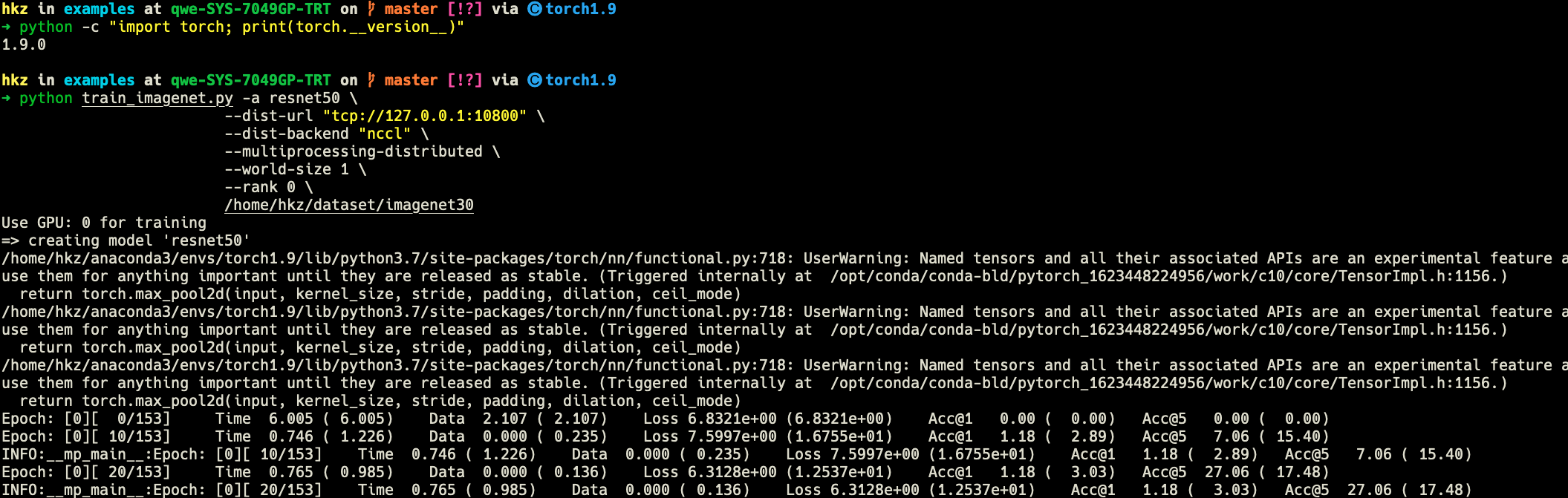
However, when torch.__version__>1.6.0, a repeated INFO exists in stdout while not exists in the log file:
Use GPU: 0 for training
=> creating model 'resnet50'
Epoch: [0][ 0/153] Time 3.884 ( 3.884) Data 1.946 ( 1.946) Loss 7.0728e+00 (7.0728e+00) Acc@1 0.00 ( 0.00) Acc@5 0.00 ( 0.00)
Epoch: [0][ 10/153] Time 0.338 ( 0.655) Data 0.000 ( 0.177) Loss 1.1332e+01 (1.1690e+01) Acc@1 3.53 ( 4.06) Acc@5 12.94 ( 15.08)
INFO:log:Epoch: [0][ 10/153] Time 0.338 ( 0.655) Data 0.000 ( 0.177) Loss 1.1332e+01 (1.1690e+01) Acc@1 3.53 ( 4.06) Acc@5 12.94 ( 15.08)
Epoch: [0][ 20/153] Time 0.340 ( 0.505) Data 0.000 ( 0.098) Loss 7.3043e+00 (9.7744e+00) Acc@1 10.59 ( 3.98) Acc@5 25.88 ( 16.75)
INFO:log:Epoch: [0][ 20/153] Time 0.340 ( 0.505) Data 0.000 ( 0.098) Loss 7.3043e+00 (9.7744e+00) Acc@1 10.59 ( 3.98) Acc@5 25.88 ( 16.75)
Epoch: [0][ 30/153] Time 0.341 ( 0.452) Data 0.000 ( 0.069) Loss 5.5403e+00 (8.6561e+00) Acc@1 4.71 ( 3.72) Acc@5 15.29 ( 16.81)
INFO:log:Epoch: [0][ 30/153] Time 0.341 ( 0.452) Data 0.000 ( 0.069) Loss 5.5403e+00 (8.6561e+00) Acc@1 4.71 ( 3.72) Acc@5 15.29 ( 16.81)
Epoch: [0][ 40/153] Time 0.341 ( 0.424) Data 0.000 ( 0.055) Loss 4.7685e+00 (7.6899e+00) Acc@1 4.71 ( 3.85) Acc@5 22.35 ( 17.27)
INFO:log:Epoch: [0][ 40/153] Time 0.341 ( 0.424) Data 0.000 ( 0.055) Loss 4.7685e+00 (7.6899e+00) Acc@1 4.71 ( 3.85) Acc@5 22.35 ( 17.27)
Epoch: [0][ 50/153] Time 0.340 ( 0.408) Data 0.000 ( 0.046) Loss 3.9618e+00 (6.9825e+00) Acc@1 0.00 ( 3.46) Acc@5 18.82 ( 17.07)
INFO:log:Epoch: [0][ 50/153] Time 0.340 ( 0.408) Data 0.000 ( 0.046) Loss 3.9618e+00 (6.9825e+00) Acc@1 0.00 ( 3.46) Acc@5 18.82 ( 17.07)
Yes! I met the same problem. It would have saved me a lot of time if I could have searched this post:). And thanks for your suggestion, I will look into loguru for an alternative solution.
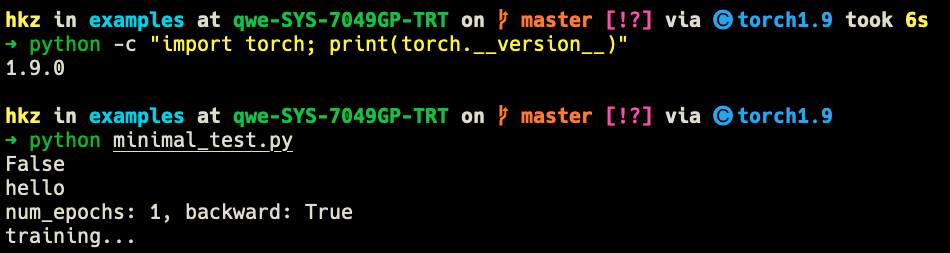
Thanks for your kind reply! I create two conda environments, torch1.6 and torch1.9 respectively.
Running the working example, I can confirm the logging issue exists in torch1.9 while not in torch1.6.
I was using a simpler test case, this is the script I was running:
import logging
import os
import sys
import torch.distributed as dist
import torch
import torch.nn.parallel
import torch.nn as nn
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group('nccl', rank=0, world_size=1)
print(logging.root.hasHandlers())
model = torch.nn.parallel.DistributedDataParallel(nn.Linear(10, 10).cuda(), device_ids=[0])
input = torch.rand(10, 10).cuda()
model(input)
class NoOp:
def __getattr__(self, *args):
def no_op(*args, **kwargs):
"""Accept every signature by doing non-operation."""
pass
return no_op
def get_logger(log_dir, log_name=None, resume="", is_rank0=True):
"""Get the program logger.
Args:
log_dir (str): The directory to save the log file.
log_name (str, optional): The log filename. If None, it will use the main
filename with ``.log`` extension. Default is None.
resume (str): If False, open the log file in writing and reading mode.
Else, open the log file in appending and reading mode; Default is "".
is_rank0 (boolean): If True, create the normal logger; If False, create the null
logger, which is useful in DDP training. Default is True.
"""
if is_rank0:
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
# StreamHandler
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(level=logging.INFO)
logger.addHandler(stream_handler)
# FileHandler
mode = "w+" if resume == "False" else "a+"
if log_name is None:
log_name = os.path.basename(sys.argv[0]).split(".")[0] + (".log")
file_handler = logging.FileHandler(os.path.join(log_dir, log_name), mode=mode)
file_handler.setLevel(level=logging.INFO)
logger.addHandler(file_handler)
else:
logger = NoOp()
return logger
logger = get_logger('/tmp/', 'foo')
logger.info('hello')
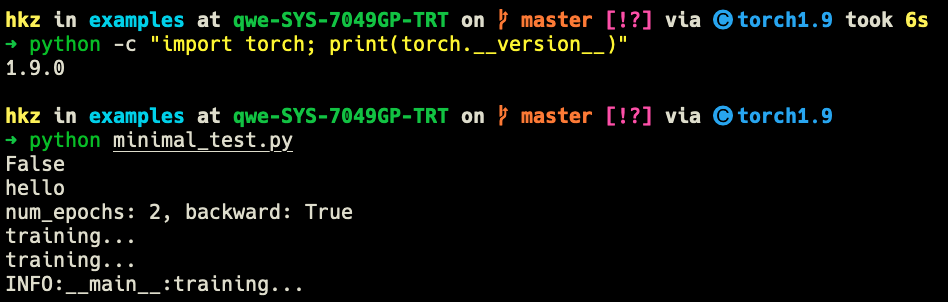
Thanks for sharing! I dive into my test code and find the function .backdward() in the training loop (>=2) is the cause of this weird behavior. Based on your minimal test code, I write the following scripts:
import logging
import os
import sys
import torch.distributed as dist
import torch
import torch.nn.parallel
import torch.nn as nn
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group('nccl', rank=0, world_size=1)
print(logging.root.hasHandlers())
model = torch.nn.parallel.DistributedDataParallel(nn.Linear(10, 10).cuda(), device_ids=[0])
criterion = nn.CrossEntropyLoss().cuda()
class NoOp:
def __getattr__(self, *args):
def no_op(*args, **kwargs):
"""Accept every signature by doing non-operation."""
pass
return no_op
def get_logger(log_dir, log_name=None, resume="", is_rank0=True):
"""Get the program logger.
Args:
log_dir (str): The directory to save the log file.
log_name (str, optional): The log filename. If None, it will use the main
filename with ``.log`` extension. Default is None.
resume (str): If False, open the log file in writing and reading mode.
Else, open the log file in appending and reading mode; Default is "".
is_rank0 (boolean): If True, create the normal logger; If False, create the null
logger, which is useful in DDP training. Default is True.
"""
if is_rank0:
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
# StreamHandler
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(level=logging.INFO)
logger.addHandler(stream_handler)
# FileHandler
mode = "w+" if resume == "False" else "a+"
if log_name is None:
log_name = os.path.basename(sys.argv[0]).split(".")[0] + (".log")
file_handler = logging.FileHandler(os.path.join(log_dir, log_name), mode=mode)
file_handler.setLevel(level=logging.INFO)
logger.addHandler(file_handler)
else:
logger = NoOp()
return logger
logger = get_logger('/tmp/', 'foo')
logger.info('hello')
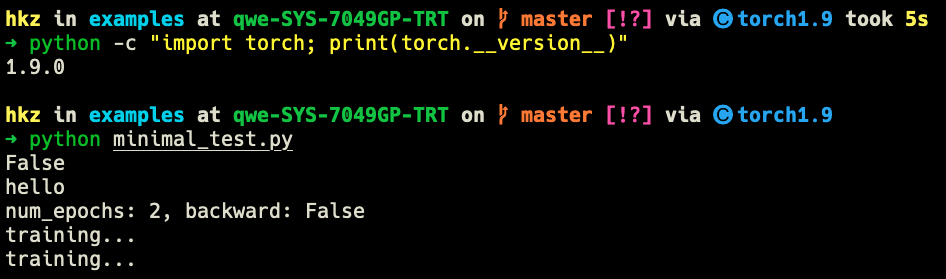
num_epochs = 2
backward = False
logger.info('num_epochs: {}, backward: {}'.format(num_epochs, backward))
for i in range(num_epochs):
input = torch.rand(10, 10).cuda()
target = torch.tensor([1]*10).cuda()
output = model(input)
loss = criterion(output, target)
if backward:
loss.backward()
logger.info('training...')
pytorch version 1.9.0, num_epochs>=2, backward=True: