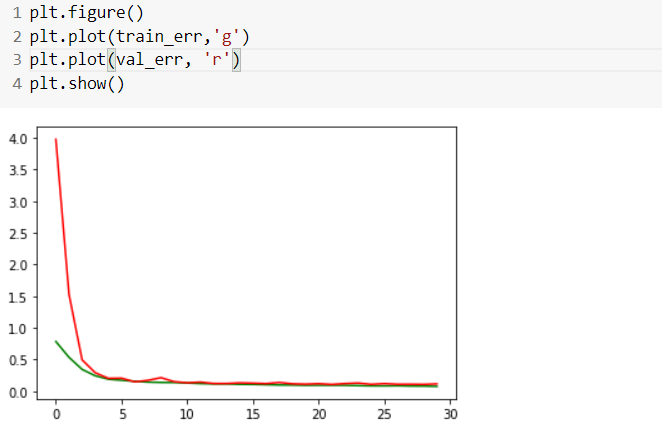
Using Unet I get very good convergence of Validation and Training Cross Entropy Loss
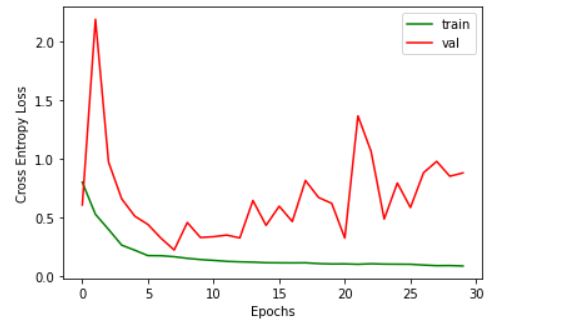
Whereas R2-UNet shows an erroneous validation loss whereas training loss converges nicely.
I am training both the models using the same batch size, Learning Rate, epochs. Is this a case of overfitting? How can I overcome this, will regularization/LR scheduling/ SGD/ Gradient Clipping help in convergence.
On a more general note how should I debug such results, is it just by trying out different things and finding out which gives the best result? Would like to know if there is mathematically intuitive approach to debugging.
Thank you in advance!
I would agree that your R2-UNet model is showing signs of overfitting. We can note that your model is training well considering that your training loss is consistently going down.
The easiest option is to simply save your model after every epoch and deploy early stopping using your validation loss. You can see that around epoch 7 your validation loss is at its best. You can use your model and that point and it’s possible that it performs well enough for your application.
Otherwise you will need to deploy methods to prevent overfitting. There’s many ways to go about this, you could add dropout to your model, you could make your model less complex, you could give it more data to train with, etc. It’s mainly going to be experimenting and see what works best for your model.
Thank you Alex for your reply!
After some inspection I realized that the R2U-Net has around 6 million parameters compared to vanilla UNet which has 1 million parameters. So in a mathematical sense a more complex model results in a curve which fits the training data points perfectly and does not generalize well to unseen data.
Early stopping would imply I am settling for an inferior model performance. If I want to improve the model performance I would have to opt for regularization and more data. Is this conclusion right?
The main conclusion would that we would need to combat overfitting. Regularization and more data is definitely a way to go about it, but there’s a handful of techniques out there. But I agree that those would be good places to start.