I have a question related to this project U-2-Net/u2net_test.py at 7e5ff7d4c3becfefbb6e3d55916f48c7f7f5858d · xuebinqin/U-2-Net · GitHub
I can trace the net like this:
traced_script_module = torch.jit.trace(net, inputs_test)
traced_script_module.save("traced_model.pt")
print(inputs_test.size()) # shows (1, 3, 320, 320)
Now I’m trying to run the model in a C++ application. I was able to do this in a prior project GitHub - DBraun/PyTorchTOP-cpumem: PyTorch / libtorch in TouchDesigner based on the CPUMemoryTOP example. I used CMake and built in debug mode by doing
SET DEBUG=1 before the CMake instructions.
In the C++ project for U-2-Net, I can load the model into a module with no errors. When I call
torchinputs.clear();
torchinputs.push_back(torch::ones({1, 3, 320, 320 }, torch::kCUDA).to(at::kFloat));
module.forward(torchinputs); // error
I get
Unhandled exception at 0x00007FFFD8FFA799 in TouchDesigner.exe: Microsoft C++ exception: std::runtime_error at memory location 0x000000EA677F1B30. occurred
The error is at pytorch/torch/csrc/jit/api/module.h at 4c0bf93a0e61c32fd0432d8e9b6deb302ca90f1e · pytorch/pytorch · GitHub It says inputs has size 0. However, I’m pretty sure I’ve passed non-empty data (1, 3, 320,320) to module->forward() PyTorchTOP-cpumem/src/PyTorchTOP.cpp at f7cd16cb84021a7fc3681cad3a66c2bd7551a572 · DBraun/PyTorchTOP-cpumem · GitHub
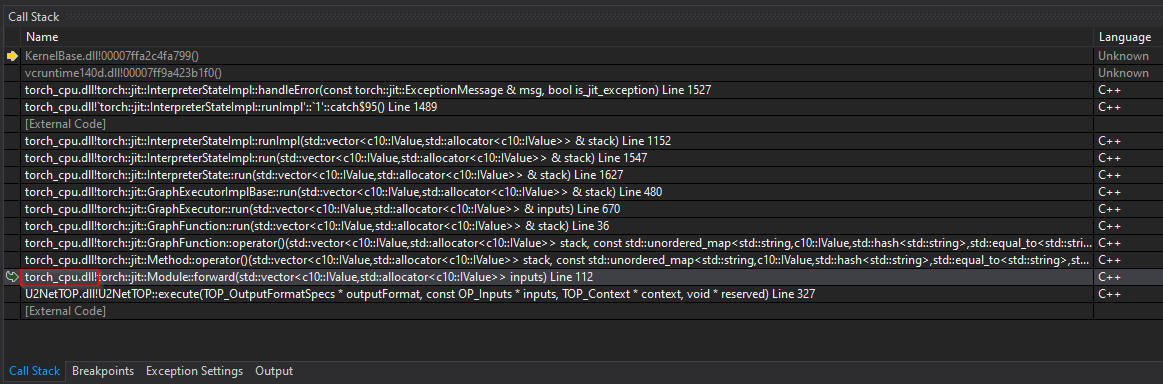
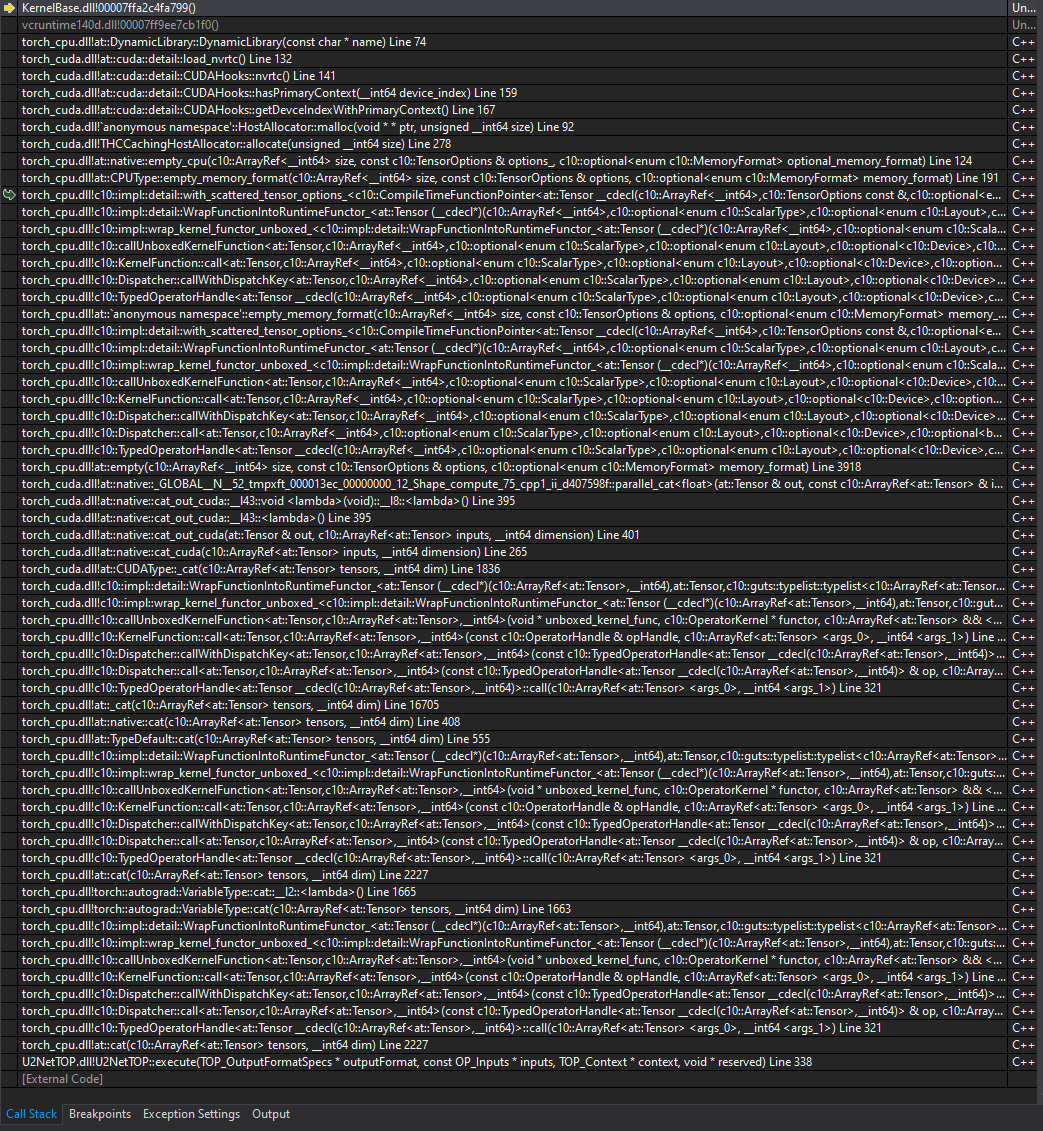
This is the stack trace at module->forward(torchinputs)
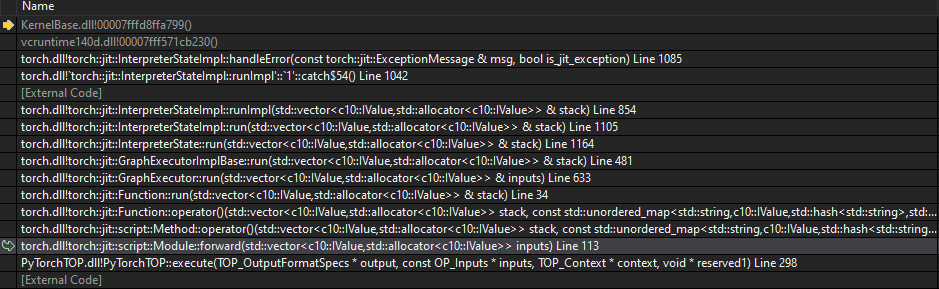
I thought it might be a DLL issue but I’ve copied all DLLs from libtorch/lib
I can confirm GPU stuff is available and that when I traced the module I was using CUDA.
LoadLibraryA("c10_cuda.dll");
LoadLibraryA("torch_cuda.dll");
try {
std::cout << "CUDA: " << torch::cuda::is_available() << std::endl;
std::cout << "CUDNN: " << torch::cuda::cudnn_is_available() << std::endl;
std::cout << "GPU(s): " << torch::cuda::device_count() << std::endl;
}
catch (std::exception& ex) {
std::cout << ex.what() << std::endl;
}
Trying to fix the runtime exception on module->forward, I thought maybe @torch.jit.script needed to be in some of the functions in the U-2-Net project like here U-2-Net/model/u2net.py at 7e5ff7d4c3becfefbb6e3d55916f48c7f7f5858d · xuebinqin/U-2-Net · GitHub I was worried about calling shape[2:] in a function without the @torch.jit.script Should I not be worried?
Any advice is appreciated!
I’ve also followed all the instructions here An unhandled exceptionMicrosoft C ++ exception: c10 :: Error at memory location - #4 by peterjc123