I am working on a model where the task is panoptic segmentation (I think thats what its called).
The input is an image and the output is a 3D Matrix where each 2D matrix is a class (I have 13 classes). I am trying to overfit a single image
The model is as follows:
- Encoder (MobileNetV4)
- Decoder (MobileNetV4 reversed with ConvTranspose2D with skip connections)
- Transformer (Takes in encoder output and outputs weights → dynamic weights)
- DynamicConv (Layer that takes the Decoder output and the Transformer’s outputs)
The Dynamic Conv layer uses the transformer outputs as weights over the Decoder output.
Decoder output might look like 1,16,256,256
Transformer output looks like this: 1, 16, 13
The final output is 1, 13, 256, 256.
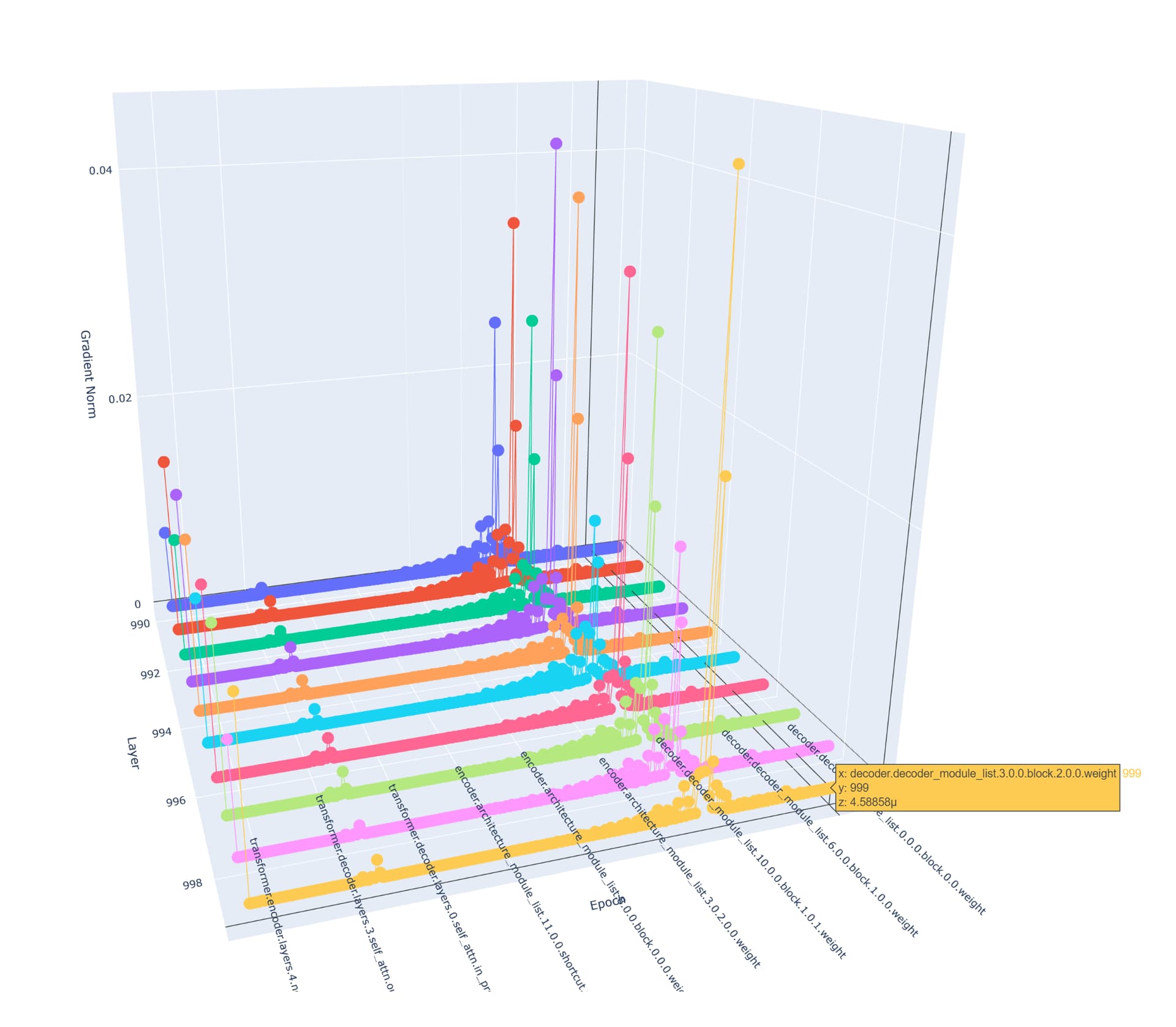
The screenshot above shows the decoder layer always has 0 for the gradients. Mind you, this is epoch 1000. But Ive also plotted the 3D gradients in earlier layers. The Transformer had bigger gradients as well. However, the Decoder layer always had 0 since the beginning. So the Transformer learned a bit?, but the Decoder did not learn.
I know my issue is related to the Decoder weights and how we are updating the weights for the decoder, I just need a sanity check from someone. Im not a researcher and just constantly trying to learn.
Early epoch:
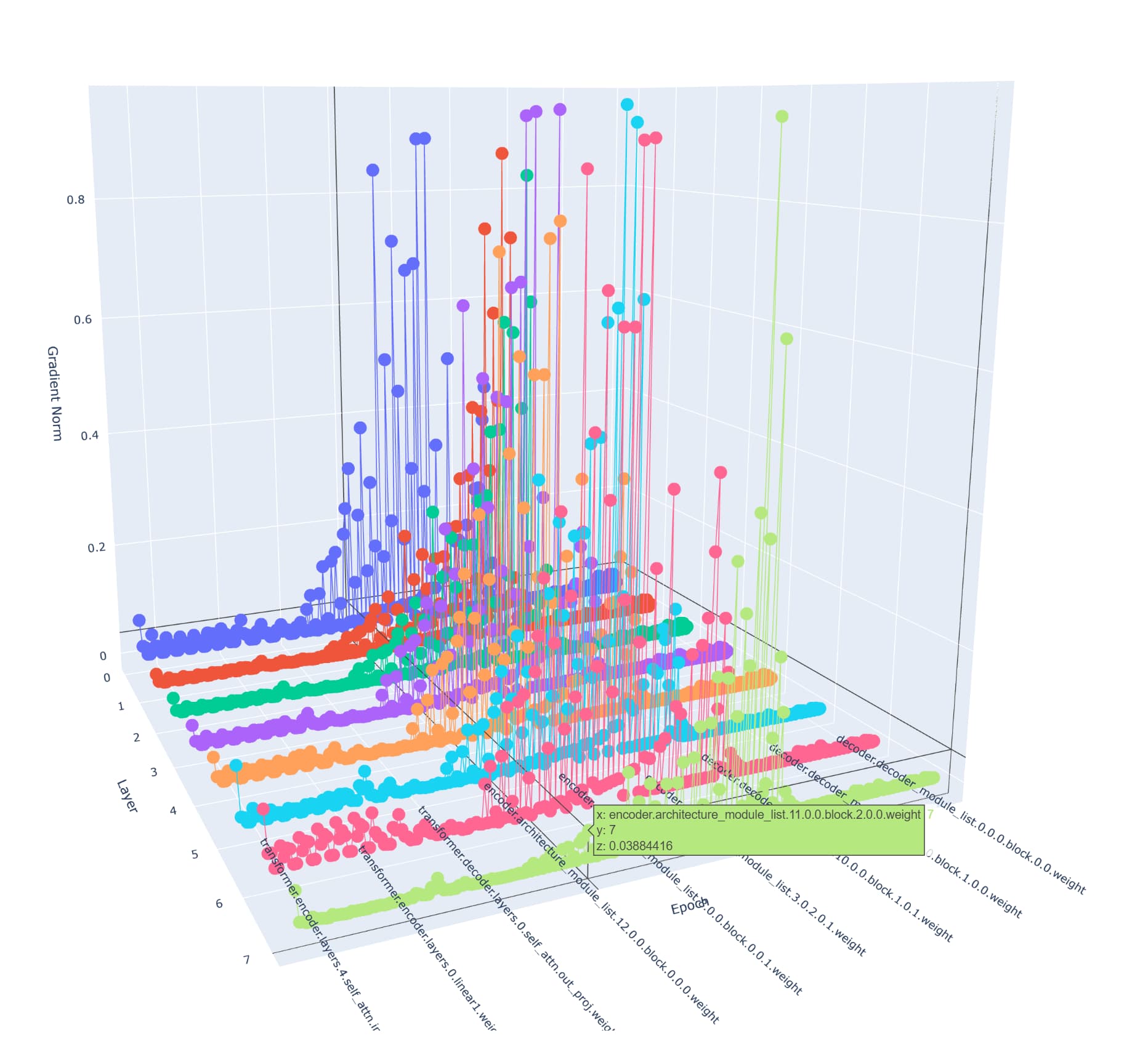
Am I right to assume that the model is not using the UNET Decoder and the Transformer effectively when learning ?
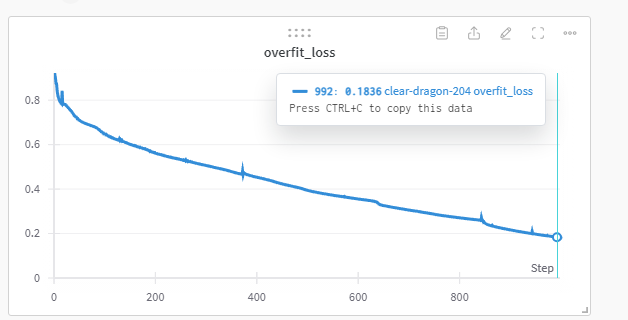
This is 1000 epoch to fit a single image with its respective 3D masks matrix