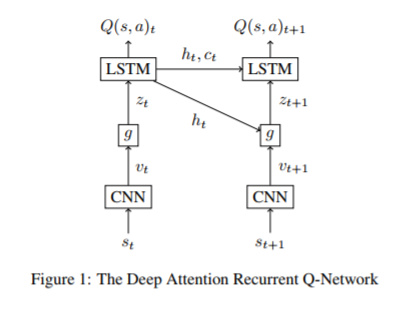
Hi, thank you for your response. I followed what you had said. It makes sense but my network gets stuck in local minima, means training error does not decrease after 3 epochs. Initially, I thought my data loading is wrong but I trained a CNN classifier with the same data loading and it gave 90%+ accuracy. Here is my model.py and train.py code (for now, I haven’t used any attention (g) function).
##model.py
import math
import torch.nn as nn
import torch.nn.functional as F
class EncoderCNN(nn.Module):
def init(self,rnn_input_size):
super(EncoderCNN, self).init()
self.conv1 = nn.Conv2d(1, 64, kernel_size=9, stride=3, padding=0)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(64, 128, kernel_size=7, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(128, 256, kernel_size=5, stride=1, padding=0)
self.pool3 = nn.MaxPool2d(2)
self.fc = nn.Linear(256x5x5, rnn_input_size)
def forward(self, x):
# (batch * seq, 1, 210, 210)
out = self.conv1(x)
out = F.relu(out)
out = self.pool1(out)
out = self.conv2(out)
out = F.relu(out)
out = self.pool2(out)
out = self.conv3(out)
out = F.relu(out)
out = self.pool3(out)
# (batch * seq, 64, 5, 5)
out = out.view(out.size(0), -1)
# (batch * seq, 64 * 5 * 5)
out = self.fc(out)
return out
class DecoderRNN(nn.Module):
def init(self, input_size, hidden_size, output_size, num_layers):
super(DecoderRNN, self).init()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = x.view(-1, 5, self.input_size)
out, _ = self.lstm(out)
out = out.contiguous().view(-1, out.size(2))
out = self.fc(out)
return out
snippet of train.py
for epoch in range(args.num_epochs):
avg_loss=0
for i in range (0,len(dataset),args.batch_size):
# Forward, Backward and Optimize
d,t=get_input(i,dataset,targets,args.batch_size)
d = to_var(d)
t = to_var(t)
# Forward, Backward and Optimize
decoder.zero_grad()
encoder.zero_grad()
features = encoder(d.view(-1,1, d.size(2), d.size(3)).float())
outputs = decoder(features)
loss = criterion(outputs, t.view(-1).long())
avg_loss=avg_loss+loss.data[0]
loss.backward()
optimizer.step()