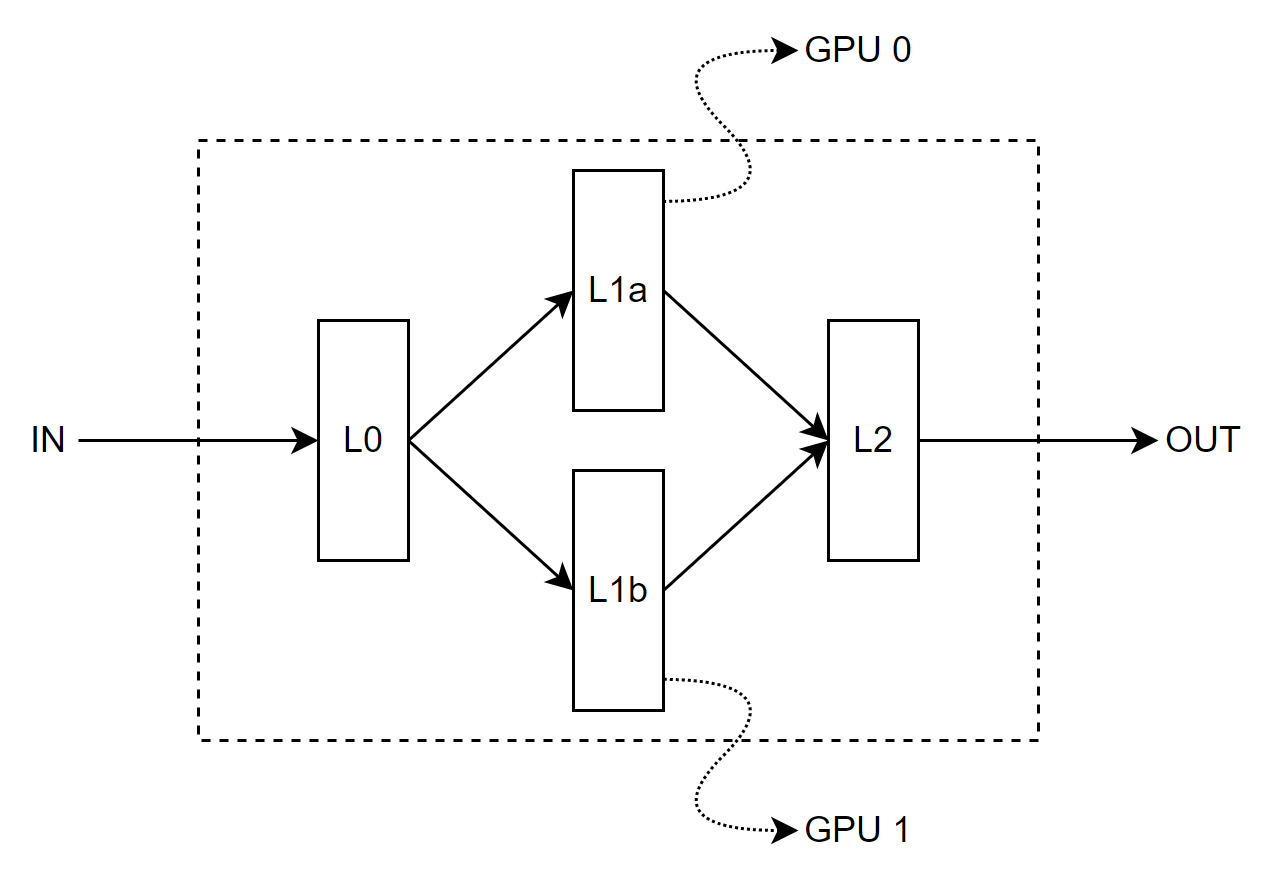
Hi, Let us assume I have a simple feedforward neural network, sketched below. I want to train this model using PyTorch. How can I train it in a way that “L1a” and “L1b” get trained (forward and backward) simultaneously on two different GPUs. Any comment is very much appreciated.
1 Like
To be more specific, I have the following code. How can I execute the “branch 0” lines and “branch 1” lines parallel on two GPUs? I have tried torch.multiprocessing, but it gives me the following error “RuntimeError: Cowardly refusing to serialize non-leaf tensor which requires_grad, since autograd does not support crossing process boundaries.”.
class Feedforward(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Feedforward, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.fc1 = torch.nn.Linear(self.input_size, self.hidden_size).to("cuda:0")
self.relu1 = torch.nn.ReLU()
self.fc2a = torch.nn.Linear(self.hidden_size, self.output_size).to("cuda:0")
self.relu2a = torch.nn.ReLU()
self.fc2b = torch.nn.Linear(self.hidden_size, self.output_size).to("cuda:1")
self.relu2b = torch.nn.ReLU()
self.fc3 = torch.nn.Linear(self.output_size, 1).to("cuda:0")
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
hidden = self.fc1(x)
relu = self.relu1(hidden)
hidden_a = self.fc2a(relu) # branch 0
relu_a = self.relu2a(hidden_a) # branch 0
hidden_b = self.fc2b(relu.to("cuda:1")) # branch 1
relu_b = self.relu2a(hidden_b) # branch 1
output = self.fc3(relu_a + relu_b.to("cuda:0"))
output = self.sigmoid(output)
return outputIs there a specific reason you want to use multiprocessing here? If you are not going to use multiple machines, you can just run this script in a single process and I believe it should achieve what you are looking for.
1 Like
@pritamdamania87, Thank you so much for your comment. I have a single machine with two GPUs. Since L1a (branch 0) and L1b (branch 1) are independent of each other, I believe I can do the forward pass on both branches simultaneously on two GPUs. In this way, I may decrease training time. Can I do this using PyTorch? Any comments are very much appreciated.
Yes you can do this with PyTorch. Note that GPU operations are asynchronous in PyTorch and the code you shared above should already work and use both GPUs simultaneously.
When you run this code:
hidden_a = self.fc2a(relu) # branch 0
relu_a = self.relu2a(hidden_a) # branch 0
The work is just enqueued asynchronously to GPU 0 and PyTorch continues execution on the CPU side and will run this code without waiting for branch 0 to complete on GPU 0:
hidden_b = self.fc2b(relu.to("cuda:1")) # branch 1
relu_b = self.relu2a(hidden_b) # branch 1
Now, finally when this code is run:
output = self.fc3(relu_a + relu_b.to("cuda:0"))
It automatically would trigger a device synchronization (due to .to(“cuda:0”)) which would in term wait for execution on GPU 0 and GPU 1 to finish before combining their output.
One small detail is that if relu is already on GPU 0, you probably might need to move relu.to("cuda:1") to a line before branch 0 and save it in a temporary variable. That would ensure when branch 1 executes, there is no dependency on branch 0.
1 Like
@pritamdamania87, I ran the code and checked GPUs computations with PyTorch Profiler. As graphs below show, GPU1 computation starts right after GPU0 finishes its own computations. Am I do something wrong here?
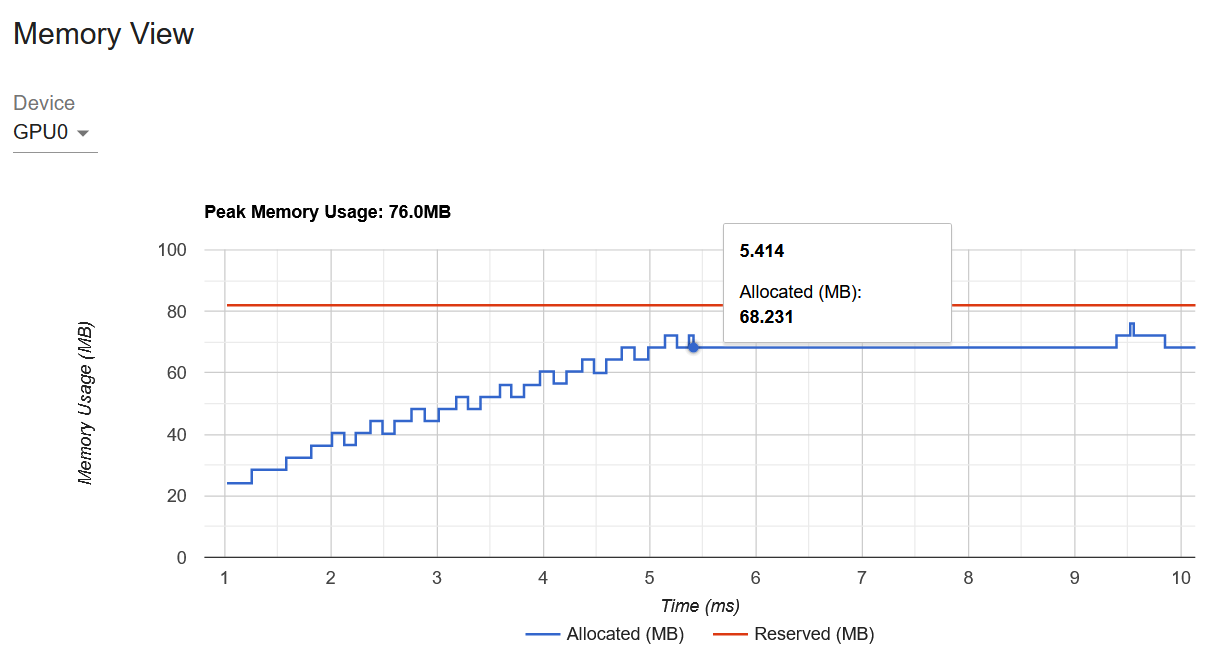
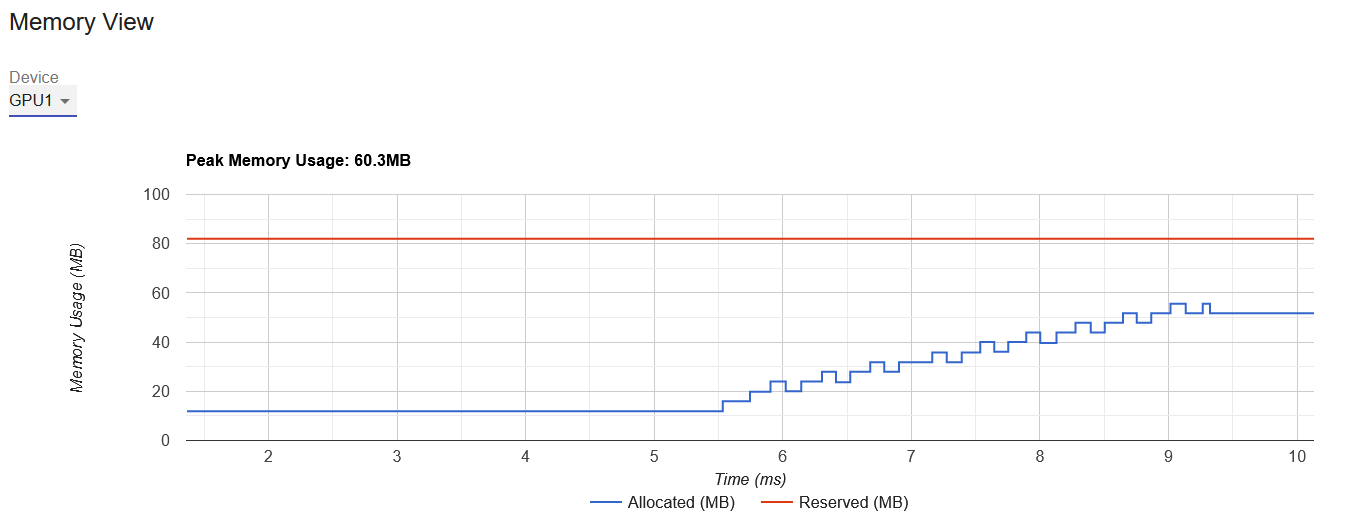
Here is my full code:
class Feedforward(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Feedforward, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.fc1 = torch.nn.Linear(self.input_size, self.hidden_size).to("cuda:0")
self.relu1 = torch.nn.ReLU()
self.fc2a = torch.nn.Linear(self.hidden_size, self.output_size).to("cuda:0")
self.relu2a = torch.nn.ReLU()
self.fc2b = torch.nn.Linear(self.hidden_size, self.output_size).to("cuda:1")
self.relu2b = torch.nn.ReLU()
self.fc3 = torch.nn.Linear(self.output_size, 1).to("cuda:0")
self.sigmoid = torch.nn.Sigmoid()
def forward_branch0(self, relu):
for i in range(10):
hidden_a = self.fc2a(relu)
relu = self.relu2a(hidden_a)
return relu
def forward_branch1(self, relu):
for i in range(10):
hidden_b = self.fc2b(relu)
relu = self.relu2b(hidden_b)
return relu
def forward(self, x):
hidden = self.fc1(x)
relu = self.relu1(hidden)
relu_b = relu.to("cuda:1")
relu_a = self.forward_branch0(relu)
relu_b = self.forward_branch1(relu_b)
output = self.fc3(relu_a + relu_b.to("cuda:0"))
output = self.sigmoid(output)
return output
# CREATE RANDOM DATA POINTS
def blob_label(y, label, loc): # assign labels
target = np.copy(y)
for l in loc:
target[y == l] = label
return target
with torch.profiler.profile(
schedule=torch.profiler.schedule(
wait=2,
warmup=2,
active=6,
repeat=1),
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
profile_memory=True,
record_shapes=True,
on_trace_ready=torch.profiler.tensorboard_trace_handler(dir_name='path-to-results'),
with_stack=True
) as profiler:
x_train, y_train = make_blobs(n_samples=1000, n_features=1000, cluster_std=1.5, shuffle=True)
x_train = torch.cuda.FloatTensor(x_train)
y_train = torch.FloatTensor(blob_label(y_train, 0, [0]))
y_train = torch.cuda.FloatTensor(blob_label(y_train, 1, [1, 2, 3]))
model = Feedforward(1000, 1024, 1024)
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
model.train()
epoch = 20
for epoch in range(epoch):
optimizer.zero_grad()
# Forward pass
y_pred = model(x_train)
# Compute Loss
loss = criterion(y_pred.squeeze(), y_train)
print('Epoch {}: train loss: {}'.format(epoch, loss.item()))
# Backward pass
loss.backward() # computes the gradients
optimizer.step() # updates the weights accordingly
profiler.step()
I used a much simpler version of your script:
import torch
class Feedforward(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Feedforward, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.fc1 = torch.nn.Linear(self.input_size, self.hidden_size).to("cuda:0")
self.relu1 = torch.nn.ReLU()
self.fc2a = torch.nn.Linear(self.hidden_size, self.output_size).to("cuda:0")
self.relu2a = torch.nn.ReLU()
self.fc2b = torch.nn.Linear(self.hidden_size, self.output_size).to("cuda:1")
self.relu2b = torch.nn.ReLU()
self.fc3 = torch.nn.Linear(self.output_size, 1).to("cuda:0")
self.sigmoid = torch.nn.Sigmoid()
def forward_branch0(self, relu):
for i in range(10):
hidden_a = self.fc2a(relu)
relu = self.relu2a(hidden_a)
return relu
def forward_branch1(self, relu):
for i in range(10):
hidden_b = self.fc2b(relu)
relu = self.relu2b(hidden_b)
return relu
def forward(self, x):
hidden = self.fc1(x)
relu = self.relu1(hidden)
relu_b = relu.to("cuda:1")
relu_a = self.forward_branch0(relu)
relu_b = self.forward_branch1(relu_b)
output = self.fc3(relu_a + relu_b.to("cuda:0"))
output = self.sigmoid(output)
return output
with torch.profiler.profile(
schedule=torch.profiler.schedule(
wait=2,
warmup=2,
active=6,
repeat=1),
activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA],
profile_memory=True,
record_shapes=True,
with_stack=True
) as profiler:
model = Feedforward(1000, 1024, 1024)
inp = torch.rand(1000, 1000, device='cuda:0')
for i in range(100):
print(f'Starting iter: {i}')
model(inp)
profiler.step()
profiler.export_chrome_trace('/tmp/chrome_trace')
When I look at the chrome trace it looks like both GPUs are being used concurrently:
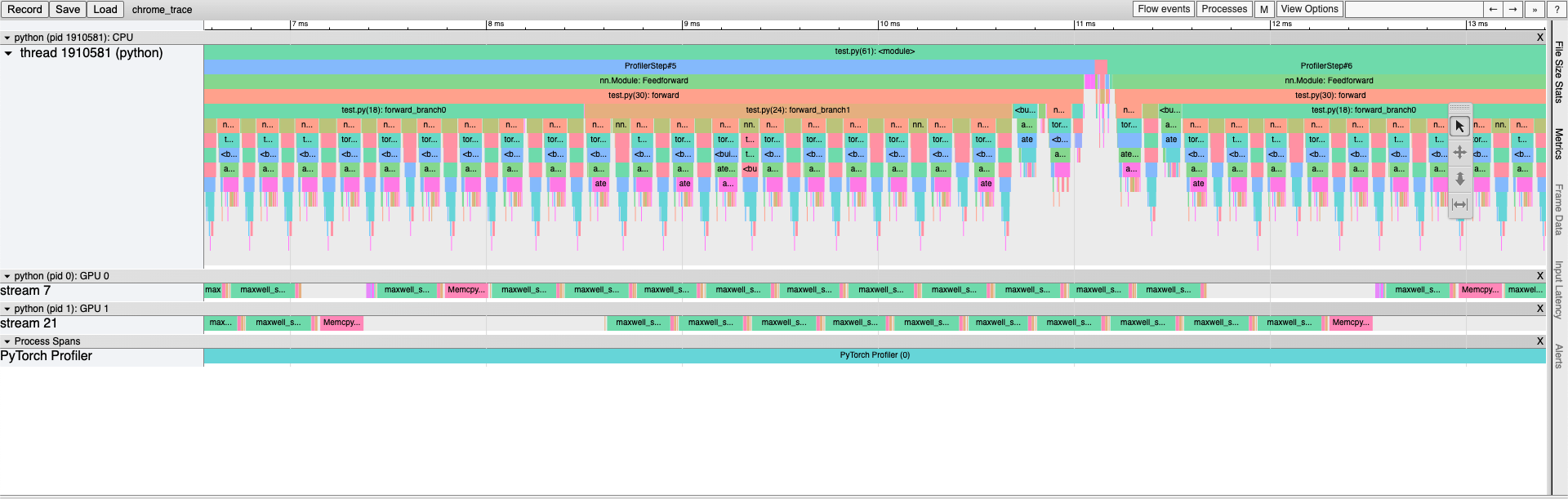
I’d say you probably want to look at GPU utilization/GPU trace to see if both GPUs are being used concurrently and not something like memory view.
1 Like
@pritamdamania87, thanks so much for your valuable response. I was able to regenerate the results.