Hi everyone
I have a stupid question,
Is anyone knows that what should be the form of loss function in an Denoising Autoencoder?
should it be like below?;
loss = criterion (model (noisy_data),noise_less_data)
basically model (noisy_data) is the model will be trained with inputs that are corrupted data and loss function calculates the difference (here MSE) between output of the model and the data that are not noisy ?
In this way that makes no sense to me. because if we already have access to noiseless data, then what’s the point of building up a denoising autoencoder?
The goal would be to train the model to be able to denoise new data.
The same question might apply to why we would like to train a model to classify dogs and cats, if we already have the labels.
That totally makes sense.
One more question:
Do u if there is any method (model) that can be do in an unsupervised way? I mean without seeing noiseless data, to Denise noisy data?
Tnx
For both noiseless data as well as noisy input of the NN, I used dataloader (I have two data loader for each) Now I am a bit of worry because the shuffle option is set to True in both data loader. Do you think this might affect my training because I should compare same pixel from the noisy data with the same pixel from the noiseless data …
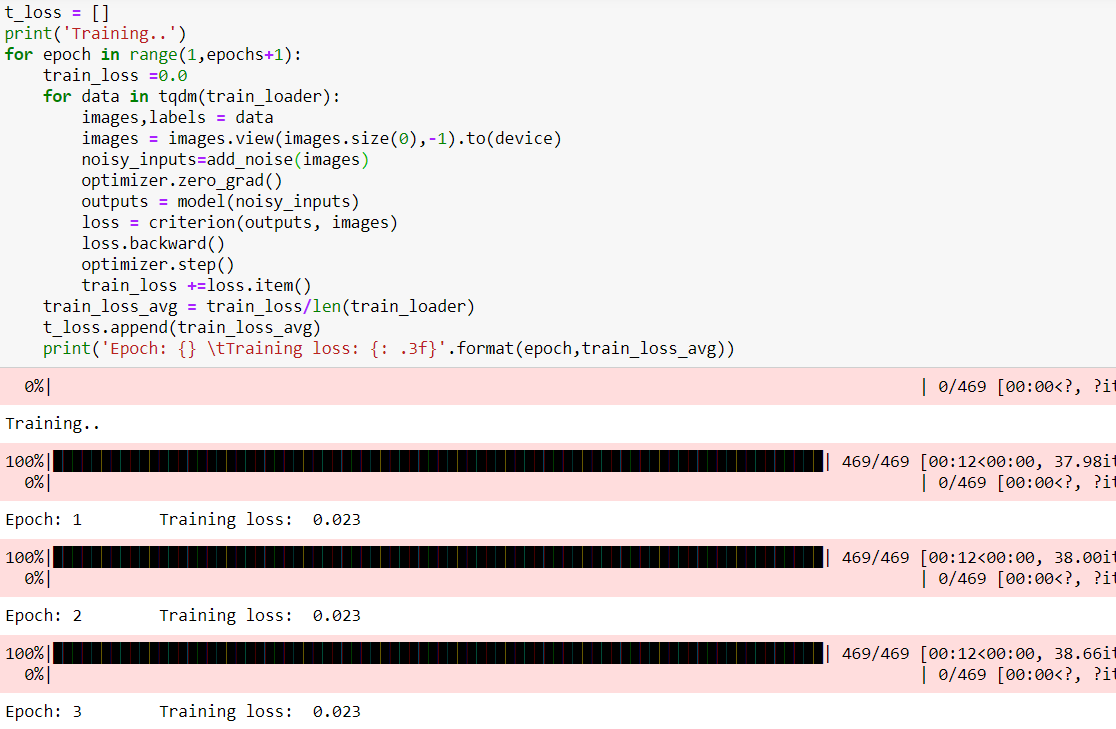
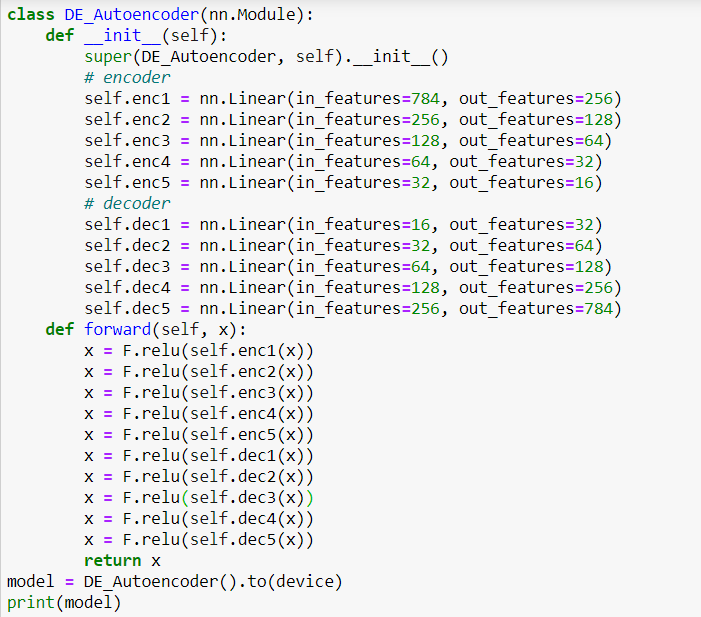
I wish to build a Denoising autoencoder I just use a small definition from another PyTorch thread to add noise in the MNIST dataset. While training my model gives identical loss results. please tell me what I am doing wrong.
The model looks generally alright, but I’m not sure if you really want to apply the last F.relu on the output. As a debugging step you could remove it and rerun your training.
PS: you can post code snippets by wrapping them into three backticks ```, which would allow to copy and debug your code