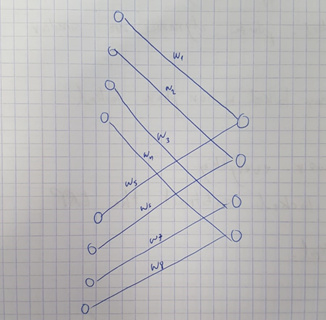
Hello, I am trying to create this dense layer:
where each neuron receives as input only a portion of the previous layers (my goal is to create a learned weighted average of the previous layers).
Shown below is the custom layer I created for this purpose but the network, using this layer, doesn’t seem to be learning.
Can anyone point out what I got wrong here and if another solution exists for my problem? Thank you.
class LinearWeightedAvg(torch.nn.Module):
def __init__(self, n_neurons):
super(LinearWeightedAvg, self).__init__()
self.neurons = []
for neur_idx in range(n_neurons):
self.neurons.append(torch.nn.Linear(2, 1))
def forward(self, *input):
outputs = []
for neur_idx, neuron in enumerate(self.neurons):
concat_inp = [[] for i in range(len(input[0]))]
for inp in input:
for example_idx, example in enumerate(inp):
concat_inp[example_idx].append(example[neur_idx])
outputs.append(neuron.forward(torch.tensor(concat_inp)))
return torch.stack(outputs).view(-1, len(self.neurons))
Also I would be careful with the weight initialization. Here I use randn for simplicity but something else should be used for sure.
Also the weight initialization of a Linear Layer depends on the sizes so might behave unexpectedly for very small numbers like you do.