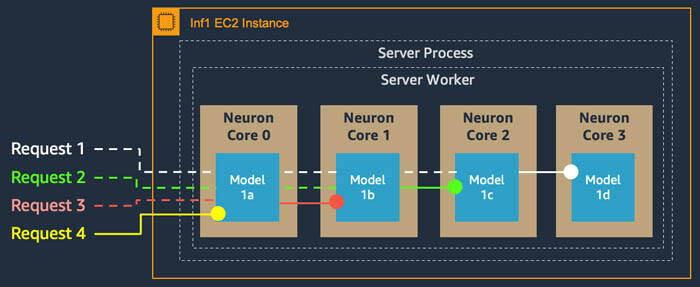
This got me thinking if I can hack the modelA, compute and modelB together into one graph, Does this sounds like a bad idea ?
Also if you had to deploy something like this how would you do it ? (just to constrain the problem lets assume we have to do all this in one container)
I noticed that you successfully converted the PaddleOCR model to PyTorch. I am currently working on this as well but am encountering some difficulties.
You can find my questions and details about the issue in this discussion: ISSUE LINK.