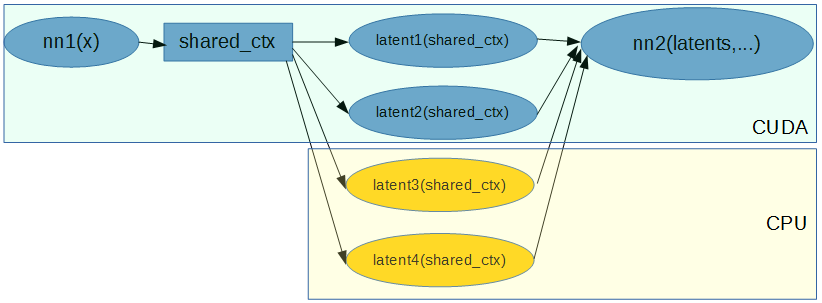
Am I correct in assuming that adding CPU operations like above makes gradient accumulation (for tensor shared_ctx) non-deterministic?
I.e. latent1backward & latent2backward are serialized, as single cuda stream is used. But CPU backward functions (and/or memory transfers) are executed concurrently, and summands for shared_ctx’s gradient can come in different orders.
Yes you are correct that when using multiple devices, the accumulation is not forced to run in a specific order.
A “simple” solution to fix that is to use a custom function that does the copy to the different devices in the forward and the accumulation in the backward (in a fixed order in your custom backward). Would that work for you?
You can for a very generic custom function to do that:
import torch
from torch.autograd import Function
class CustomScatter(Function):
@staticmethod
def forward(ctx, tensor, devices):
ctx.inp_device = tensor.device
outs = tuple(tensor.to(d) for d in devices)
return outs
@staticmethod
def backward(ctx, *grads):
res = 0.
for g in grads:
res += g.to(ctx.inp_device)
return res, None
torch.manual_seed(123)
a = torch.rand(2, requires_grad=True)
devices = ["cpu", "cpu", "cuda", "cuda"]
all_t = CustomScatter.apply(a, devices)
loss = 0.
for t in all_t:
loss += a * t.to("cpu")
loss.sum().backward()
print(a.grad)
is latent3backward and latent4backward accumulation order deterministic?
As long as they are “ready to run” (meaning that all their inputs are ready) at the same time and that they ran in the same order during the forward pass yes.