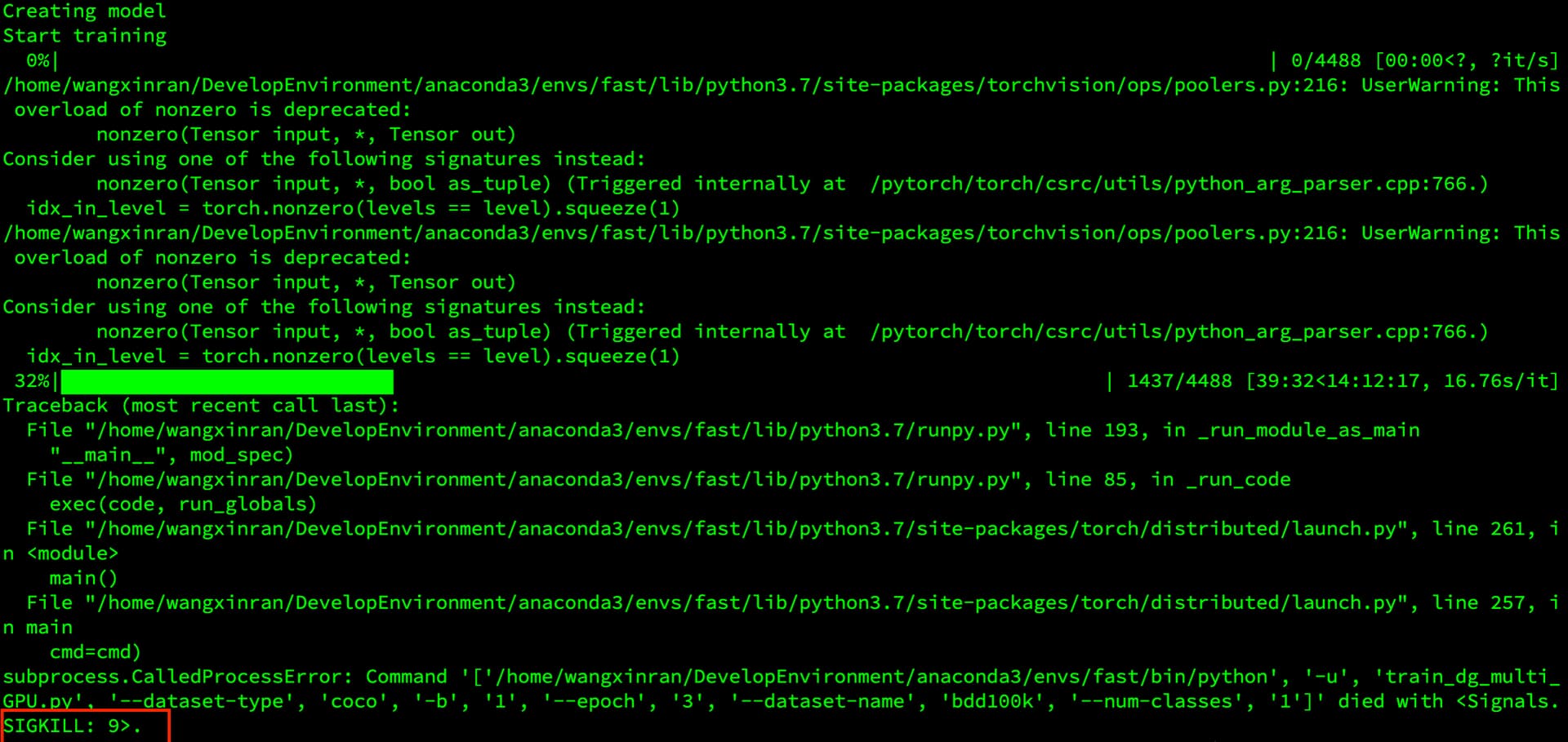
There is no out of memory. I really don’t know how to fix these. Please give me some help.
This is the code of each epoch.
def train_one_epoch_dg(model, optimizer, data_loaders, device, epoch, batch_size,
print_freq=50, warmup=False):
length_list = [len(data_loader) for data_loader in data_loaders]
max_length = max(length_list)
cycle_data_loaders = list()
for data_loader in data_loaders:
if len(data_loader) < max_length:
cycle_data_loaders.append(cycle(data_loader))
else:
cycle_data_loaders.append(data_loader)
model.train()
# metric_logger = utils.MetricLogger(delimiter=" ")
# metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
lr_scheduler = None
if epoch == 0 and warmup is True: # 当训练第一轮(epoch=0)时,启用warmup训练方式,可理解为热身训练
warmup_factor = 1.0 / 1000
warmup_iters = min(1000, max_length - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
mloss = torch.zeros(1).to(device) # mean losses
enable_amp = True if "cuda" in device.type else False
for i in tqdm(range(0, max_length)):
images_list = list()
targets_list = list()
for j in range(len(data_loaders)):
[images, targets] = next(iter(cycle_data_loaders[j]))
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
images_list.extend(images)
targets_list.extend(targets)
with torch.cuda.amp.autocast(enabled=enable_amp):
loss_dict = model(images_list, targets_list)
losses = sum(loss for loss in loss_dict.values())
# reduce losses over all GPUs for logging purpose
loss_dict_reduced = utils.reduce_dict(loss_dict)
losses_reduced = sum(loss for loss in loss_dict_reduced.values())
loss_value = losses_reduced.item()
# 记录训练损失
mloss = (mloss * i + loss_value) / (i + 1) # update mean losses
if not math.isfinite(loss_value): # 当计算的损失为无穷大时停止训练
print("Loss is {}, stopping training".format(loss_value))
print(loss_dict_reduced)
sys.exit(1)
optimizer.zero_grad()
losses.backward()
optimizer.step()
if lr_scheduler is not None: # 第一轮使用warmup训练方式
lr_scheduler.step()
now_lr = optimizer.param_groups[0]["lr"]
return mloss, now_lr
It’s unclear where the SIGKILL was coming from based on the posted image, so I would check dmesg and see if some “guard processes” were activated and killed your process. Also, is this a shared machine where other users might want to “stop” processes?
I would guess you are running out of host memory (CPU) as you would otherwise see the typical “CUDA: out of memory” error in your script and not a SIGKILL.
I would try to check which part of the code is using the majority of the memory and see if this is indeed necessary. E.g. I don’t completely understand your data loading logic, but in case you are trying to preload the samples and store them in images_list, maybe stick to lazily loading the samples.
Thank you for your reply. In this code, I have to load images from dataloaders equally, which means I need a batch that contains the same num of images from each dataset. images_list is used to combine the tensors from each dataloader. More question: Is there any tools or codes that could help me “check which part of the code is using the majority of the memory.”
This problem has been solved now!
The bug is that when you zip or cycle image DataLoader, there might be a memory leakage! So, the memory of the CPU taken by training will be increasing with time going.
The code is updated:
def train_one_epoch_dg(model, optimizer, data_loaders, device, epoch, warmup=False, print_freq=50):
length_list = [len(data_loader) for data_loader in data_loaders]
max_length = max(length_list)
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
model.train()
lr_scheduler = None
if epoch == 0 and warmup is True: # 当训练第一轮(epoch=0)时,启用warmup训练方式,可理解为热身训练
warmup_factor = 1.0 / 1000
warmup_iters = min(1000, max_length - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
mloss = torch.zeros(1).to(device) # mean losses
enable_amp = True if "cuda" in device.type else False
dataloader_iterator_1 = iter(data_loaders[1])
for i, [images_0, targets_0] in enumerate(metric_logger.log_every(data_loaders[0], print_freq, header)):
images_list = list()
targets_list = list()
images = list(image.to(device) for image in images_0)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets_0]
images_list.extend(images)
targets_list.extend(targets)
try:
[images_1, targets_1] = next(dataloader_iterator_1)
except:
dataloader_iterator_1 = iter(data_loaders[1])
[images_1, targets_1] = next(dataloader_iterator_1)
images = list(image.to(device) for image in images_1)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets_1]
images_list.extend(images)
targets_list.extend(targets)
with torch.cuda.amp.autocast(enabled=enable_amp):
loss_dict = model(images_list, targets_list)
del images_list, targets_list
losses = sum(loss for loss in loss_dict.values())
# reduce losses over all GPUs for logging purpose
loss_dict_reduced = utils.reduce_dict(loss_dict)
losses_reduced = sum(loss for loss in loss_dict_reduced.values())
loss_value = losses_reduced.item()
# 记录训练损失
mloss = (mloss * i + loss_value) / (i + 1) # update mean losses
if not math.isfinite(loss_value): # 当计算的损失为无穷大时停止训练
print("Loss is {}, stopping training".format(loss_value))
print(loss_dict_reduced)
sys.exit(1)
optimizer.zero_grad()
losses.backward()
optimizer.step()
if lr_scheduler is not None: # 第一轮使用warmup训练方式
lr_scheduler.step()
metric_logger.update(loss=losses_reduced, **loss_dict_reduced)
now_lr = optimizer.param_groups[0]["lr"]
metric_logger.update(lr=now_lr)
return mloss, now_lr
Sorry, I am not clear about MAE, but as I mentioned in this question, the kill problem may be caused by memory leakage. You should check your code to see which part may cause such a problem.
Thank you so much for your reply! I found that changing “num_workers=b” to “num_workers=a” (a is smaller than b) or “num_workers=0” was of great help though setting num_workers as a or 0 cost me more time to pretrain the model. That is because command “num_workers=b” means that b workers load the data into RAM and make the memory overhead bigger.