can someone explain to me the difference between detach().clone() and clone().detach() for a tensor A = torch.rand(2,2)
what is the difference between A.detach().clone() and A.clone().detach()
are they equal?
when i do detach it makes requres_grad false, and clone make a copy of it, but how the two aforementioned method are different?
If you first detach the tensor and then clone it, the computation path is not copied, the other way around it is copied and then abandoned. Other than that, the methods should be identical.
Thus I’d recommend to first detach and then copy because it does not make sense to copy anything that is never used.
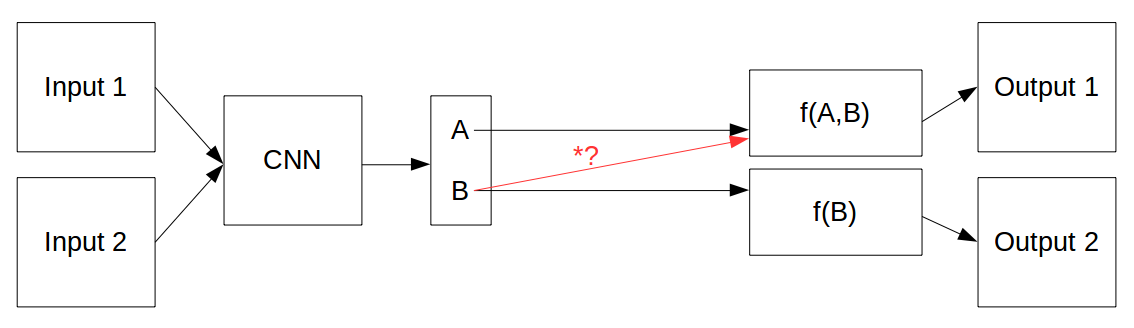
Say along the top decoder branch you don’t want to backprop over B, you only want to use it as a fixed input to f(A,B)…would you want to use B.detach() in place of *? or would that prevent the bottom branch from learning over B because you have completely detached it from the computational graph?
This is a circumstance where I feel like using B.clone().detach() would still allow learning over B in the lower branch and allow B as input to the top branch as a fixed input without requires_grad.
I think doing B.detach() would be sufficient there.
b_det = B.detach()
would create a new tensor that is detached from the previous computation graph.
However, they still share the same memory and you can still use B for the lower part. You could maybe check some GAN examples, where this is also common, when you only want to train discriminators on the output of a generator.
I am having trouble understanding this. I think the main issue I am having is because I do not understand .clone()'s semantics. The docs (torch.Tensor — PyTorch 2.1 documentation) say:
Returns a copy of the self tensor. The copy has the same size and data type as self .
NOTE: Unlike copy_(), this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor.
I don’t understand what the point of recording the clone in the graph. Like what is the difference with doing:
import torch
import torch.nn as nn
a = torch.tensor([1,2,3.], requires_grad=True)
b = a # a copy of a, at least by reference in python
c = a.clone() # a copy of a by reference AND records operation in backward
d = torch.nn.Identity()(a) # same as c except it has different name for identity vs cloning
it seems to me that the only addition is that clone() records the operation in the graph, which seems really weird to. Why do we ever want to do this?
What is the difference between the above 4 operations? What is the use of clone? @albanD
b = a in python actually gives you the same Tensor. So there is nothing to “record”.
If you do a clone, you get a new Tensor (object and memory). And so if you want the backward to work, you need to have a way to propagate gradients from the new Tensor to the original one.
But the underlying memory the share is the same, right? So in effect it looks like they are truly the same except that python isn’t aware of it…right?
There are three cases here:
Same Tensor object
Different Tensor object but looking at the same memory (a view)
Different Tensor object looking at different memory.
For example:
You get the first one when you do new = base
You can get the second one by doing new = base.view_as(base)
You can get the third one by doing new = base.clone()
Just for me to understand what “different tensor objects mean”. Does that mean they are a different instance of the Tensor class and might also have additional meta-data that is different (for some reason)?
Trying to understand what different tensors really means.
Sorry for the spam Alban. I am just trying to understand the terminology clearly.
So “a new tensor” means a “new tensor instance/object” and not a new allocation of memory for a matrix/tensor data. Right?
Is “memory of a tensor” the same thing as its “view”? I think I read you saying “they have the same view” and it confused me. I always thought view was the same as shape but now I am unsure. Do you mind clarifying that for me?
I am referring to this:
Different Tensor object but looking at the same memory (a view)
So “a new tensor” means a “new tensor instance/object” and not a new allocation of memory for a matrix/tensor data. Right?
Yes
You can see the Tensor as being two things (not the actual implementation):
A class instance containing metadata
A raw pointer to the memory containing the data
When I say that a Tensor is a view of another, I mean that they different instances of the Tensor class but they point to the same memory containing the data.
Basically .detach().clone() is the one you should do and the difference is essentially negligible. Operationally they are essentially equivalent with the one I mentioned being slightly more efficient but probably negligible.
I see. So basically it seems that “view” means they are different tensor objects this with different meta-data (main example is different “shape”, in fact I always thought shape and view were the same) pointing to the same memory.
PyTorch allows a tensor to be a View of an existing tensor. View tensor shares the same underlying data with its base tensor. Supporting View avoids explicit data copy, thus allows us to do fast and memory efficient reshaping, slicing and element-wise operations.