Hi!
So I am trying to calculate the average mean squared error over my validation dataset. I’ve done this in two ways: using Ignite’s Loss metric, where the loss_fn = nn.MSELoss() and then using Ignite’s MeanSquaredError metric, as can be seen in the code snippets below:
loss_fn = torch.nn.MSELoss()
metrics = {
"mse": Loss(
loss_fn,
output_transform=lambda infer_dict: (infer_dict["y_pred"], infer_dict["y"]),
),
}
for name, metric in metrics.items():
metric.attach(engine, name)
vs.
metrics = {
"mse": MeanSquaredError(
output_transform=lambda infer_dict: (infer_dict["y_pred"], infer_dict["y"]),
),
}
for name, metric in metrics.items():
metric.attach(engine, name)
I obtain two different results, as can be sceen from the two images below.
MeanSquaredError (the top left is evaluation MSE error, and top right is training MSE error):
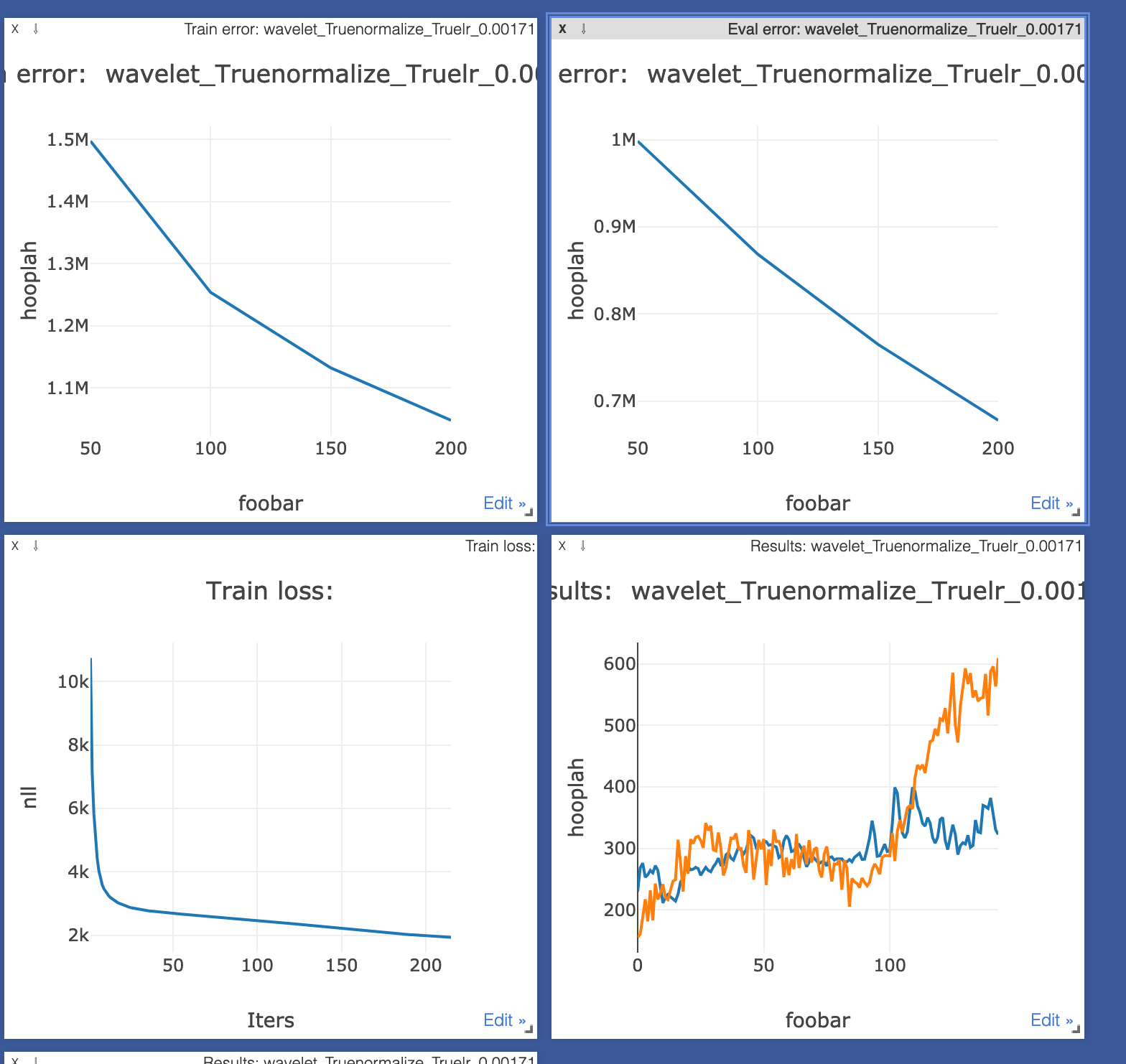
Loss:

We can see that MSE has an error of the order of “M” whereas Loss has an error of the order of “K”. What accounts for this difference?
Initially I thought that its probably because Loss() probably calculates the average mean squared error per batch, and then takes the average of the averages, whereas MeanSquaredError (from what I saw in the source code) keeps track of all squared errors, and takes the average of all the squared errors across all the batches (so it only does one average, not average of averages). However, since the batch size is constant, the two results should be numerically equivalent. For example:
( (((7^2) + (8^2) + (13^2))/3) + (((3^2) + (6^2) + (11^2))/3) ) / 2
is the same as:
(7^2) + (8^2) + (13^2) + (3^2) + (6^2) + (11^2)/6
because both groups in the first example have 3 elements in them.
Therefore, what accounts for the difference in magnitudes of the error functions?
Thanks so much!