From the source code of torch.nn.MSELoss you can see that the class is a wrapper for torch.nn.functional.mse_loss. The relevant part of the code for this one is (source code link):
if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
if target.requires_grad:
ret = (input - target) ** 2
if reduction != 'none':
ret = torch.mean(ret) if reduction == 'mean' else torch.sum(ret)
else:
expanded_input, expanded_target = torch.broadcast_tensors(input, target)
ret = torch._C._nn.mse_loss(expanded_input, expanded_target, _Reduction.get_enum(reduction))
return ret
So, as you can see if target requires gradient the operations are exactly the same as your code (hence, the gradient is the same).
If target does not require gradient the C module implementation of MSE is used. I don’t know how it is implemented in C module but I would say that it is the same calculation. Anyway, just wait for someone more informed about this.
Training outcome is consistently different in my problem. I wonder if anyone has an explanation for this. Does error is all put to input when target.requires_grad=False?
I’m also wondering why the output of nn.MSELoss is different to torch.mean((output-labels)**2).
I tried both on my code and the results differ.
I tried all kinds of mse loss calculations:
It seems like that 1,2,3 all give the same result as do 4,5,6 but the results between those two groups differ. Why is this the case? I wonder if it has to do with the precision used in C since MSELoss calls the C api, could this be the case?
If the relative errors are in the range ~1e-6, the difference is most likely caused by the limited floating point precision and a different order of operations in these approaches.
Thanks. I have to correct myself after some extra study on the results. It is nog the loss which gives different results. I think, but am not sure, that the backward() function might run differently for both groups I talked about before.
I ran the code while printing both version of the loss: 1. torch.mean(torch.square(output - labels)) and using 2. nn.MSELoss(). Every iteration they give the exact same result.
However, when using method 1. in my model to train on, the results (and following losses) differ from those while using method 2. to train on.
Again, in both cases both loss-functions give the same result every iteration:
Using 1. to train on gives a loss of 2.771e-1 (for both methods), my trainable parameter values are R = 1.120 and C = 8.881e-1.
Using 2. to train on gives a loss of 3.639e-1 (for both methods), my trainable parameter values are R = 1.388 and 9.691e-1
My question is, is it expected to get different results while using method 1. instead of 2.? And why is this probably be the case?
For each approach I used 20 000 epochs. I used random seeds to have the same output every time.
I noticed that the first ~2000 epochs the values of R en C (parameters I added to the model to fit) are the same using both approaches (1. torch.mean(torch.square(output - labels)) and 2. criterion = nn.MSELoss()) . After these epochs, the values start to differ. Here I show you the training timelines of Parameter C: Using 1. torch.mean(torch.square(output - labels)) Using 2. criterion = nn.MSELoss()
Again, the only thing I changed was the method I used to describe the loss, although they should be (and are) the same. Both losses give identical every epoch, but when using method 1. to learn on, the parameters are getting other values then when the model is learned on method 2. (as shown in the figures). Therefore, other losses are found between both methods.
I am just wondering why this difference shows up. Since the losses are the same during training, but different if it trains on the other loss-function, I thought it might be the case that the backward function works differently for both approaches.
Both approaches might create small rounding errors due to the different order of operations.
Rerunning the scripts with different seeds multiple times using both approaches should show similar convergence pattern. I.e. the number of converged runs vs. non-converged ones should approx. be the same for an increasing number of reruns.
I would not expect that these small differences would create different results, but your general training might be sensitive to these small changes.
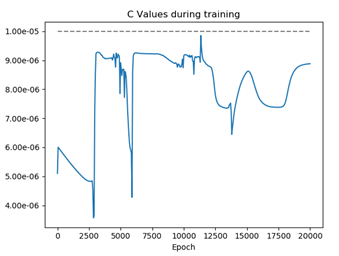 Using 1.
Using 1. 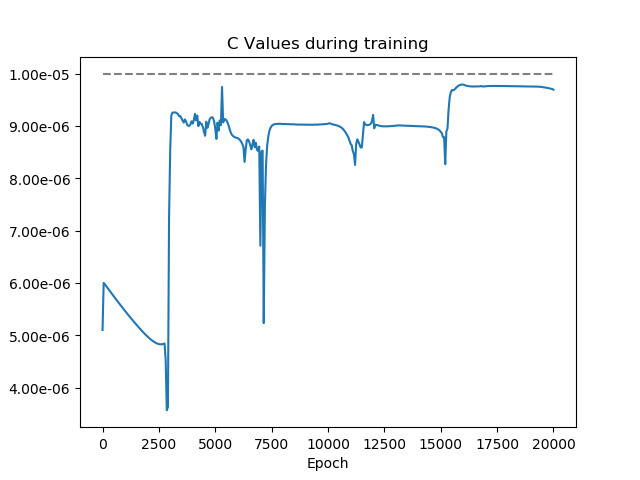 Using 2.
Using 2.