Hi,
I tried the latest two versions of PyTorch respectively 1.7.1 and 1.7.1+cpu.
I see a really big difference in memory usage for the same model between the two. I run the model on CPU only never allocate anything on GPU (checked with nvidia-smi).
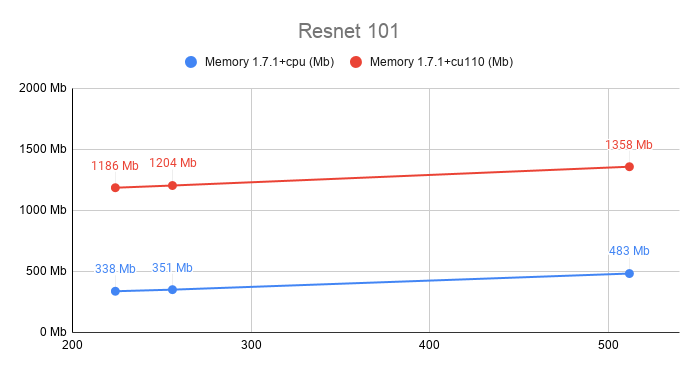
Vertical axis is memory usage, and horizontal axis is input size
(1, 3, size, size) where size take three values 224, 256, 512.I don’t find anything that make this huge difference, since the code is the same. I installed the two packages versions on different virtualenvs.
here is the code to reproduce
import torch
import argparse
from memory_profiler import memory_usage
from torchvision import models
from torch.utils import mkldnn as mkldnn_utils
import time
parser = argparse.ArgumentParser()
parser.add_argument("size", type=int, default=224)
parser.add_argument("iter", type=int, default=100)
parser.add_argument("-m", "--mkldnn", action="store_true")
parser.add_argument("-c", "--cache", action="store_true")
args = parser.parse_args()
def forward(
net,
use_mkldnn=False,
iteration=1,
weight_cache=False,
size=224,
):
net.eval()
batch = torch.rand(1, 3, size, size)
if use_mkldnn:
net = mkldnn_utils.to_mkldnn(net)
batch = batch.to_mkldnn()
if weight_cache:
# using weight cache which will reduce weight reorder
fname = "test.script.pt"
traced = torch.jit.trace(net, batch, check_trace=False)
script = traced.save(fname)
net = torch.jit.load(fname)
start_time = time.time()
for i in range(iteration):
with torch.no_grad():
net(batch)
print(
f"time: {(time.time() - start_time) / iteration}, iteration: {iteration}"
)
net = models.resnet101(False)
iter_cnt = 100
memory_snap = memory_usage(
(
forward,
(net,),
{
"use_mkldnn": args.mkldnn,
"iteration": iter_cnt,
"weight_cache": args.cache,
"size": args.size,
},
)
)
print(f"Size: {args.size}, memory_usage: {max(memory_snap)}")
I ran:
python3 test_memory.py 224 10
python3 test_memory.py 256 10
python3 test_memory.py 512 10
Could someone explain me why this behavior is happening ?
Thanks.