Hello everyone,
I’m Léo, Ph.D. Student in deep learning, and my first post in this forum is to ask a question that has already been asked several times. However, none of the answers could solve my problem.
I’m well aware that the implementation of a GRU layer differs between Keras and Pytorch, but I’m surprised that it changes that much. I start using PyTorch a few weeks ago, and I’m maybe doing something wrong. Can you spot my mistakes?
To make it short:
when inferring a given tensor to GRU layer in Keras and PyTorch, the result is entirely different.
tensor = [1,2,3,4,5,6,7,8,9,10]
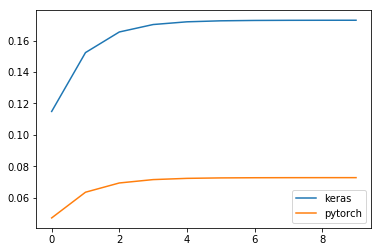
To make it long:
You can find below two codes allowing you to reproduce the results of a 1-cell GRU with Keras and the same GRU with PyTorch.
I made sure that
- the activation and recurrent activation functions are identical for both frameworks,
- All weights are initialized to 1 to remove any difference that might be due to random initialization.
- The seed is fixed so two successive runs will always give the same result.
Keras
import keras.backend as K
import tensorflow as tf
import keras.layers as kl
import keras.models as km
from tensorflow import set_random_seed
import numpy as np
import matplotlib.pyplot as plt
K.clear_session()
k_t = np.array([1,2,3,4,5,6,7,8,9,10]).reshape(1, 10, 1)
# Set the seed for reproductability
np.random.seed(12345)
set_random_seed(12345)
# Create minimal keras mbodel
inp = kl.Input((10,1))
rnn = kl.GRU(1, return_sequences=True, activation='tanh', recurrent_activation='sigmoid', kernel_initializer="ones", recurrent_initializer="ones", bias_initializer="ones")(inp)
model = km.Model(input=inp, output=rnn)
keras_result = model.predict(k_t)[0]
plt.plot(keras_result.squeeze())
plt.title("%.4f <> %.4f" % (keras_result.mean(), keras_result.std()))
plt.show()
PyTorch
import torch
import numpy as np
import matplotlib.pyplot as plt
t_t = torch.from_numpy(np.array([1,2,3,4,5,6,7,8,9,10]).reshape(1, 10, 1)).float()
# Set the seed for reproductability
np.random.seed(12345)
torch.manual_seed(12345)
rnn = torch.nn.GRU(input_size=1, hidden_size=1, num_layers=1, batch_first=True, bidirectional=False)
# Initialization (so it is identical to keras)
for name, param in rnn.named_parameters():
if 'bias' in name:
torch.nn.init.ones_(param)
elif 'weight_ih' in name:
torch.nn.init.ones_(param)
elif 'weight_hh' in name:
torch.nn.init.ones_(param)
pytorch_result, _ = rnn(t_t)
pytorch_result = pytorch_result.detach().numpy()[0]
plt.plot(pytorch_result.squeeze())
plt.title("%.4f <> %.4f" % (pytorch_result.mean(), pytorch_result.std()))
plt.show()
Sorry for the long post, I’m really stuck here.
Thank for reading