Hi, @ptrblck
In [43]: model.eval()
Out[43]:
localatt(
(fc1): Linear(in_features=13, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=512, bias=True)
(do2): Dropout(p=0.5)
(blstm): LSTM(512, 128, batch_first=True, dropout=0.5, bidirectional=True)
(fc3): Linear(in_features=256, out_features=2, bias=True)
)
x = torch.randn(10, 120, 13)
output_all = model(x, torch.tensor([120]*10))
output_1 = model(x[:5], torch.tensor([120]*5))
output_2 = model(x[5:], torch.tensor([120]*5))
output_stacked = torch.cat((output_1, output_2), dim=0)
print(torch.allclose(output_all, output_stacked))
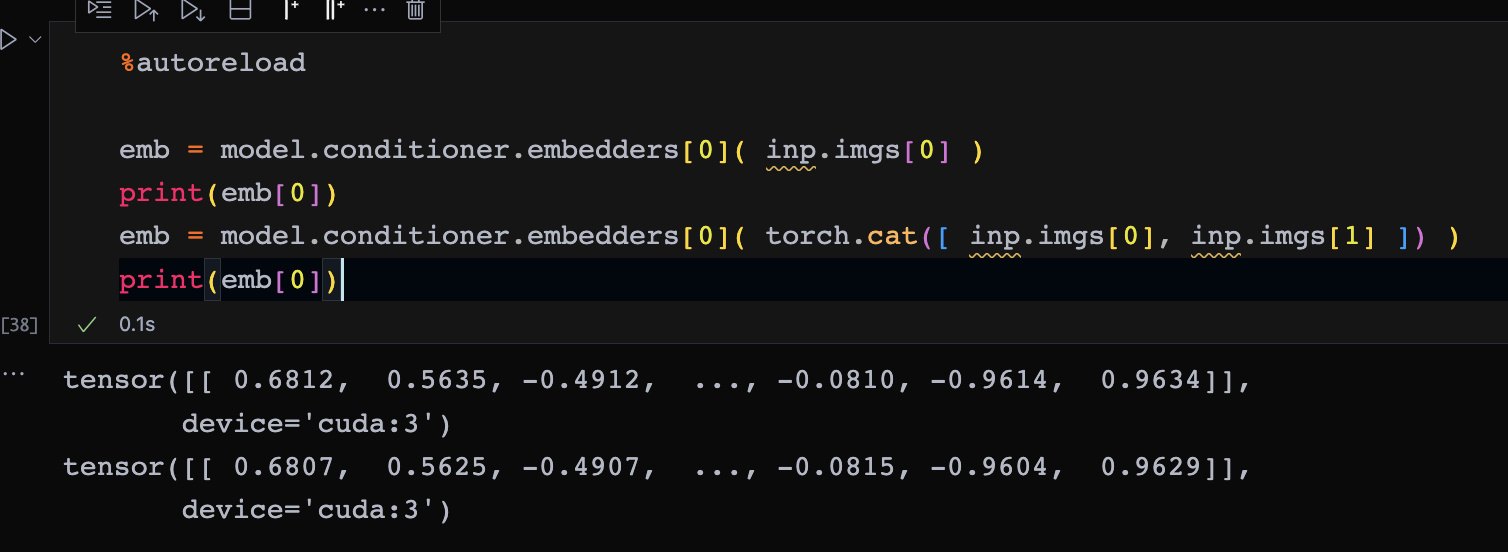
I got the result False. the results of each output is below
In [51]: output_all
Out[51]:
tensor([[0.0013, 0.9987],
[0.0016, 0.9984],
[0.0019, 0.9981],
[0.0014, 0.9986],
[0.0013, 0.9987],
[0.0016, 0.9984],
[0.0012, 0.9988],
[0.0014, 0.9986],
[0.0015, 0.9985],
[0.0017, 0.9983]], grad_fn=<SoftmaxBackward>)
In [52]: output_1
Out[52]:
tensor([[0.0286, 0.9714],
[0.0316, 0.9684],
[0.0338, 0.9662],
[0.0296, 0.9704],
[0.0281, 0.9719]], grad_fn=<SoftmaxBackward>)
In [53]: output_2
Out[53]:
tensor([[0.0316, 0.9684],
[0.0278, 0.9722],
[0.0297, 0.9703],
[0.0304, 0.9696],
[0.0323, 0.9677]], grad_fn=<SoftmaxBackward>)
In [54]: output_stacked
Out[54]:
tensor([[0.0286, 0.9714],
[0.0316, 0.9684],
[0.0338, 0.9662],
[0.0296, 0.9704],
[0.0281, 0.9719],
[0.0316, 0.9684],
[0.0278, 0.9722],
[0.0297, 0.9703],
[0.0304, 0.9696],
[0.0323, 0.9677]], grad_fn=<CatBackward>)
My model definition is below.
class localatt(nn.Module):
def __init__(self, featdim, nhid, ncell, nout):
super(localatt, self).__init__()
self.featdim = featdim
self.nhid = nhid
self.fc1 = nn.Linear(featdim, nhid)
self.fc2 = nn.Linear(nhid, nhid)
self.do2 = nn.Dropout()
self.blstm = tc.nn.LSTM(nhid, ncell, 1,
batch_first=True,
dropout=0.5,
bias=True,
bidirectional=True)
self.u = nn.Parameter(tc.zeros((ncell*2,)))
# self.u = Variable(tc.zeros((ncell*2,)))
self.fc3 = nn.Linear(ncell*2, nout)
self.apply(init_linear)
def forward(self, inputs, lens):
batch_size = inputs.size()[0]
indep_feats = inputs.view(-1, self.featdim) # reshape(batch)
indep_feats = F.relu(self.fc1(indep_feats))
indep_feats = F.relu(self.do2(self.fc2(indep_feats)))
batched_feats = indep_feats.view(batch_size, -1, self.nhid)
packed = pack_padded_sequence(batched_feats, lens, batch_first=True)
output, hn = self.blstm(packed)
padded, lens = pad_packed_sequence(output, batch_first=True, padding_value=0.0)
alpha = F.softmax(tc.matmul(padded, self.u))
return F.softmax((self.fc3(tc.sum(tc.matmul(alpha, padded), dim=1))))
Are there some problems in my model? thanks very much