Hi,
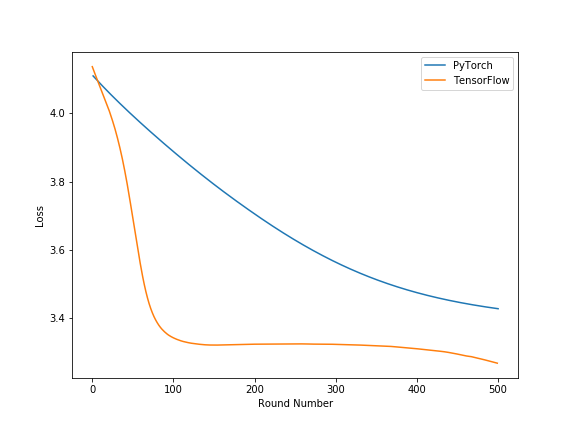
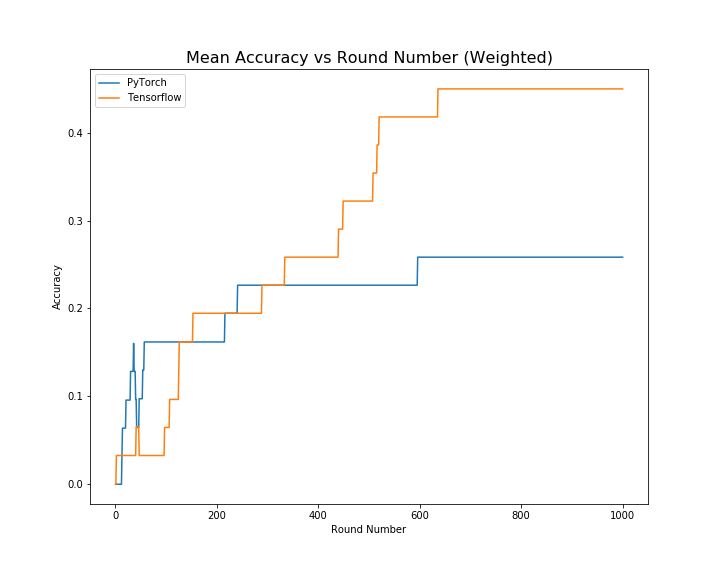
I am trying to train CNN model using TensorFlow and PyTorch but I am getting different results. I have initialized same weights to both frameworks. Attached is the result from both platforms:
PyTorch Model
class FemnistNet(nn.Module):
def __init__(self):
super(FemnistNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2)
self.pool1 = nn.MaxPool2d(2, stride=2, )
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2)
self.pool2 = nn.MaxPool2d(2, stride=2)
self.fc1 = nn.Linear(3136, 2048)
self.fc2 = nn.Linear(2048 ,62)
def forward(self, x):
x = x.view(-1, 1, 28, 28)
x = self.conv1(x)
x = th.nn.functional.relu(x)
x = self.pool1(x)
x=self.conv2(x)
x = th.nn.functional.relu(x)
x = self.pool2(x)
x = x.flatten(start_dim=1)
x = self.fc1(x)
l1_activations = th.nn.functional.relu(x)
x = self.fc2(l1_activations)
x = x.softmax()
return x, l1_activations
Tensorflow
features = tf.placeholder(
tf.float32, shape=[None, IMAGE_SIZE * IMAGE_SIZE], name='features')
labels = tf.placeholder(tf.int64, shape=[None], name='labels')
input_layer = tf.reshape(features, [-1, IMAGE_SIZE, IMAGE_SIZE, 1])
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
name = "conv1")
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
name = "conv_last")
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
# dense = tf.layers.dense(inputs=pool2_flat, units=2048, name='dense1', kernel_regularizer=tf.contrib.layers.l2_regularizer(0.001), bias_regularizer=tf.contrib.layers.l2_regularizer(0.001))
dense = tf.layers.dense(inputs=pool2_flat, units=2048, name='dense1')
act_1 = tf.nn.relu(dense)
logits = tf.layers.dense(inputs=act_1, units=self.num_classes)
predictions = {
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
# loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# cross_entropy = -tf.one_hot(labels,62) * tf.log(predictions["probabilities"] + 1e-7)
values = tf.one_hot(labels, 62) * tf.log(predictions["probabilities"] + 1e-7)
reduced_values = tf.reduce_sum(values)
batch_size = tf.shape(labels)[0]
loss = - reduced_values / tf.cast(batch_size, tf.float32)#tf.reduce_mean(cross_entropy, axis=-1)
# TODO: Confirm that opt initialized once is ok?
train_op = self.optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
eval_metric_ops = tf.count_nonzero(tf.equal(labels, tf.argmax(predictions["probabilities"], axis=1)))
Can anyone please explain the difference? Is there any padding implementation difference in both platforms? Can the padding create any difference? Thanks.