The docs here: http://pytorch.org/docs/optim.html explain how to set different learning rates for each layer in the model. However, I have a slightly different problem - I need to be able to set different learning rates for each weight within a layer. More specifically, I would like the weights connected to earlier output nodes to have a higher learning rate than those connected to later nodes, as is perhaps better explained by this picture:
Any ideas as to how I might go about implementing this?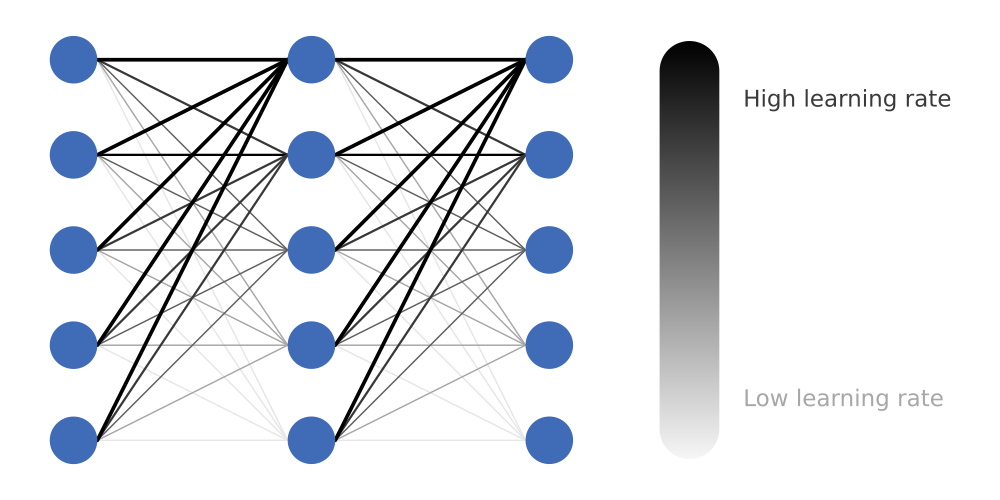
The parameters() in the per-parameter options example be any iterables for the parameters, so if you had a list of parameters_per_step and a list of learning_rates_per_step, you can do optim.SGD([{'params': p, 'lr': l} for p,l in zip(parameters_per_timestep, learning_rates_per_step)]) or somesuch.
Best regards
Thomas
2 Likes
Many thanks, but I’m not sure I entirely understand. The parameters() include the weights and biases of the network, both of which are multidimensional, so how would this translate into the parameters_per_step?
If you have them as separate instances of Parameter, you can arrange them however you want manually.
If you only have one large multi-dimension Parameter, you could multiply the parameters .grad by an appropriate weight after the backward and before the optimizer call to get something similar to a different learning rate.
Best regards
Thomas
1 Like
So how would I extract each of the weights from a torch.nn.Linear layer as a separate instance of Parameter?
No, in this case, you could go for the workaround described above (multiply the .grad with something (say torch.exp(-delta*torch.arange(0,4)).unsqueeze(1) if you have the example from your other thread). For SGD this will be the same as having learning rates smaller for the later rows of the weight.
Or you could first define separate tensors and torch.cat/torch.stack them.
Best regards
Thomas
1 Like
Hello,
please consider the following code:
There are multiple layers before this affine operation and activation layer
self.fc1 = nn.Linear(13824, 4096)
torch.nn.init.kaiming_normal_(self.fc1.weight)
self.batchnorm_fc1 = nn.BatchNorm1d(4096)
I start creating multiple heads here as the output, however YH[0] for instance has a product of numbers (you might call it weights) around 10k while YL has product of numbers of around ~400. I would like to treat each of those layers (and their weight) differently when it comes to their learning rates, otherwise the gradient is propagating through all those 400+10000+… numbers which overlooks the significance of YL sub-band output which is the most significant in my case. What do you recommend?!
#YL
self.fc3 = nn.Linear(4096, 3* 11* 13)
torch.nn.init.kaiming_normal_(self.fc3.weight)
self.batchnorm_fc3 = nn.BatchNorm1d( 3* 11* 13)
#YH[0]
self.fc4 = nn.Linear(4096, 3* 3* 29* 39)
torch.nn.init.kaiming_normal_(self.fc4.weight)
self.batchnorm_fc4 = nn.BatchNorm1d( 3* 3* 29* 39)
#YH[1] there are two more layers here
#YH[2]
with the forward:
x = F.leaky_relu( self.batchnorm_fc1(self.fc1(x)) )
###############
xl = self.fc3(x)
xl = xl .view(-1, 3, 11, 13)
xh=[]
xh.append(self.fc4(x))
xh[0] = xh[0].view(-1,3, 3, 29, 39)
##same done with the xh[1] and xh[2]
# return the output
return xl,xh
I am using those 4 output heads for constructing an inverse wavelet signal (2d) but that isn’t so important right now.