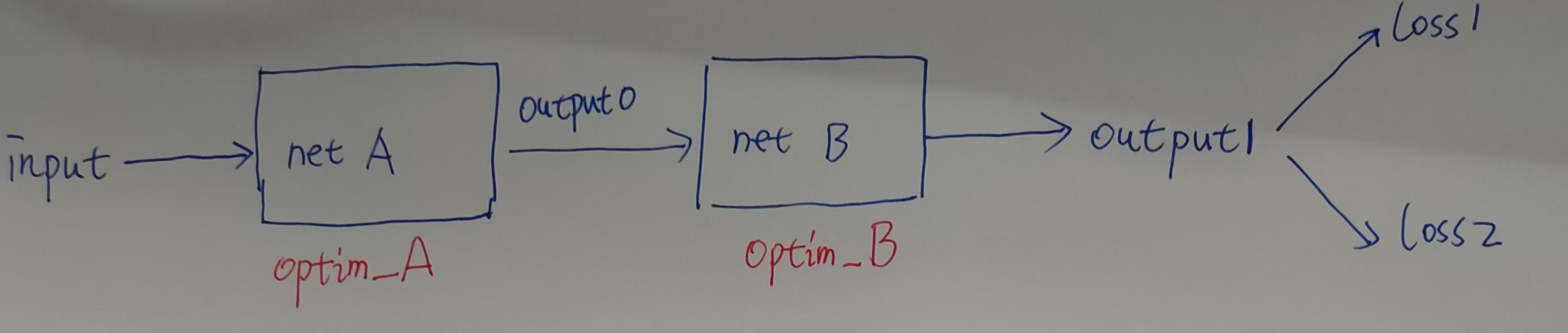
Hi Yongjie!
Your process it mostly correct. You need to use retain_graph = True
in your first backward() call:
loss1.backward (retain_graph = True)
No, one forward pass is enough. (You do, of course, have to calculate
both loss1 and loss2.) But you do need two backward() passes.
(If you weren’t to use retain_graph = True in your first backward()
pass, you would have to perform a second forward pass to rebuild the
computation graph for use by the second backward() pass.)
Here is an illustrative script:
import torch
print (torch.__version__)
weights1A = None # net1 weights after net1 half-update
weights2A = None # net2 weights after net2 half-update
weights1B = None # net1 weights after full update
weights2B = None # net2 weights after full update
for updateMethod in range (3): # update model with two "half-updates" vs. one full update
torch.manual_seed (2021) # make initialization reproducible
net1 = torch.nn.Linear (2, 2) # create new, freshly-initialized model
net2 = torch.nn.Linear (2, 2)
input = torch.randn (2)
target1 = torch.randn (2)
target2 = torch.randn (2)
opt1 = torch.optim.SGD (net1.parameters(), lr = 0.1)
opt2 = torch.optim.SGD (net1.parameters(), lr = 0.2)
if updateMethod == 0: # net1 half-update
output = net2 (torch.tanh (net1 (input)))
loss1 = torch.nn.MSELoss() (output, target1)
loss1.backward()
opt1.step()
weights1A = net1.weight.detach().clone()
elif updateMethod == 1: # net2 half-update
output = net2 (torch.tanh (net1 (input)))
loss2 = torch.nn.MSELoss() (output, target2)
loss2.backward()
opt2.step()
weights2A = net2.weight.detach().clone()
elif updateMethod == 2: # perform full update with a single forward pass
output = net2 (torch.tanh (net1 (input)))
loss1 = torch.nn.MSELoss() (output, target1) # net1 update
loss1.backward (retain_graph = True) # keep graph for net2 loss2.backward()
opt1.step()
weights1B = net1.weight.detach().clone()
opt2.zero_grad() # zero out net2 grads populated by loss1.backward()
loss2 = torch.nn.MSELoss() (output, target2) # net2 update
loss2.backward()
opt2.step()
weights2B = net2.weight.detach().clone()
print ('weights1A = ...')
print (weights1A)
print ('weights1B = ...')
print (weights1B)
print ('check weights1:', torch.allclose (weights1A, weights1B))
1
print ('weights2A = ...')
print (weights2A)
print ('weights2B = ...')
print (weights2B)
print ('check weights2:', torch.allclose (weights2A, weights2B))
Here is its output:
1.9.0
weights1A = ...
tensor([[-0.4652, 0.0495],
[ 0.3326, 0.2997]])
weights1B = ...
tensor([[-0.4652, 0.0495],
[ 0.3326, 0.2997]])
check weights1: True
weights2A = ...
tensor([[-0.6444, 0.6545],
[-0.2909, -0.5669]])
weights2B = ...
tensor([[-0.6444, 0.6545],
[-0.2909, -0.5669]])
check weights2: True
Best.
K. Frank