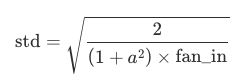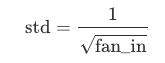In any case, it may be that your’s may unfortunately be affected. I’d probably also go with the replacement thing now as this appears not to be an unusual case
Yeah, I read they had problems with dying cores in the very beginning, I am going to post on NVIDIA dev forums tomorrow in search of some kind of utility to check the CUDA cores.
I am running the model on non-faulty GPU and I have noticed that kaiming_normal_ initialization makes my losses go up substantially. However, I had the same behavior of a model with the kaiming_normal_ initialization on my home rig with GTX 1080Ti. Is there a reason why Kaiming normal initialization substantially increases the training loss?
Is there a reason why Kaiming normal initialization substantially increases the training loss?
No, there shouldn’t be a specific reason for Kaiming/He increasing the training loss – personally, I only notices minor differences. Actually, the default Kaiming He (normal) initialization scheme and PyTorch’s default initialization schemes look relatively similar.
Kaiming (normal) uses:
with a=0 by default.
The PyTorch default uses:
when i see that correctly from
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
But since the sqrt is in the denominator, it can be much larger. So you probably want to lower your learning rate when using kaiming_normal_. Would be curious to hear what happens if you do that. Maybe choose the learning rate as follows:
Thank you for your suggestion, I will try to do this on my simple toy model which I have built yesterday, which has exactly same problem for some reason; I have seen the increase in the training loss for up to x100 times.
I had a very similar problem with RTX 2080 Ti. I ran the same code on three different GPUs - GTX 1050, TITAN X and RTX 2080Ti. The training process goes fine on GTX 1050 and TITAN X, but on RTX 2080Ti the loss decreases for a few steps and finally raises fast up to a random guessing level (Accuracy achieves a random efficiency). Sometimes I observed NaNs, but not often. In my case, the problem was my own loss function, which I implemented as follow:
Using PyTorch’s torch.nn.CrossEntropyLoss with labels instead one hots, the training process on all three GPUs goes fine. I am guessing the problems is numerical properties of my function, but I am wondering why it works on GTX 1050 and TITAN X, but not on RTX 2080Ti?
Using torch.nn.CrossEntropyLoss solves the problem, but makes impassible mixuping or label smoothing.
In our case it was a faulty GPU that we sent back to the manufacturer for replacement. When the replacement came, the model worked just like it was intended to.