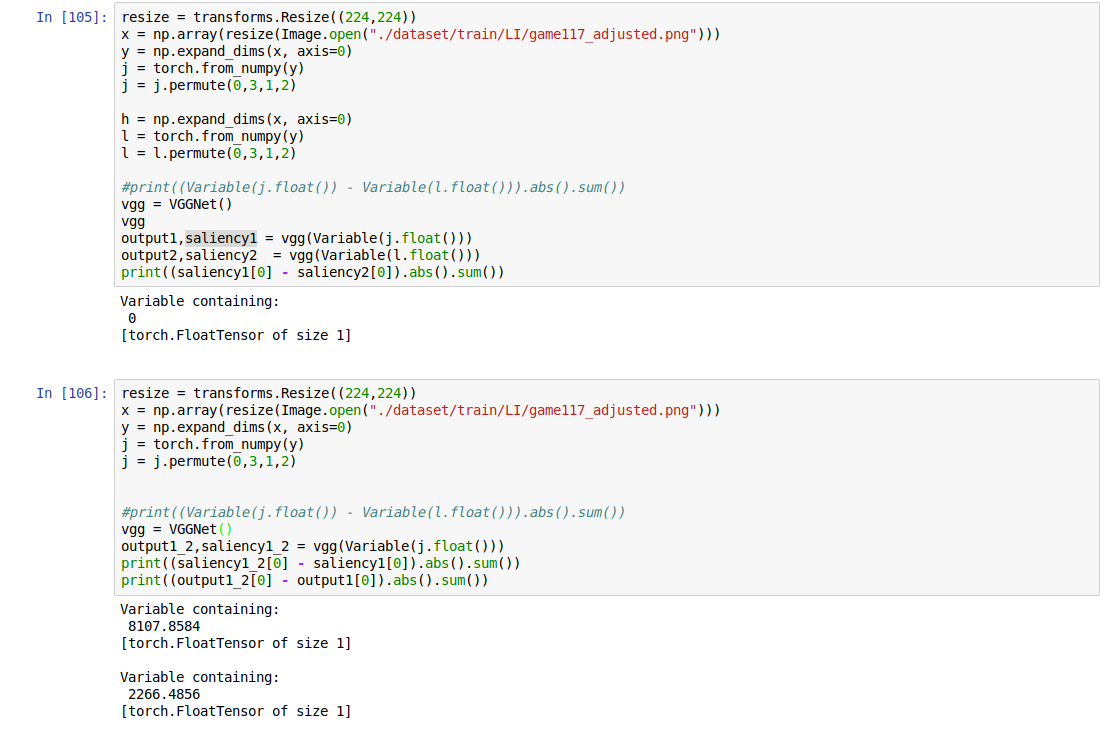
class VGGNet(nn.Module):
def init(self):
“”“Select conv1_1 ~ conv5_1 activation maps.”“”
super(VGGNet, self).init()
self.select = [15,22,29]
self.features = torch.nn.Sequential(
# conv1
torch.nn.Conv2d(3,64,3,padding=35),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 64, 3, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, stride=2),
# conv2
torch.nn.Conv2d(64, 128, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(128, 128, 3, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, stride=2),
# conv3
torch.nn.Conv2d(128, 256, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, 3, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, stride=2),
# conv4
torch.nn.Conv2d(256, 512, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, 3, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, stride=2),
# conv5
torch.nn.Conv2d(512, 512, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, 3, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, 3, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, stride=2)
)
self.deconv1 = torch.nn.Sequential(
torch.nn.ConvTranspose2d(256, 128, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(128, 64, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(64, 1, 3, padding=0,stride=1),
torch.nn.ReLU(),
)
self.deconv2 = torch.nn.Sequential(
torch.nn.ConvTranspose2d(512, 256, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(256, 128, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(128, 64, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(64, 1, 3, padding=0,stride=1),
torch.nn.ReLU(),
)
self.deconv3 = torch.nn.Sequential(
torch.nn.ConvTranspose2d(512, 512, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(512, 256, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(256, 128, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(128, 64, 4, stride=2),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(64, 1, 3, padding=0,stride=1),
torch.nn.ReLU(),
)
self.final_attention_pred = torch.nn.Sequential(
torch.nn.ConvTranspose2d(9, 1, 3, stride=1,padding=1)
)
self._initialize_weights()
def _initialize_weights(self):
# initializing weights using ImageNet-trained model from PyTorch
for i, layer in enumerate(models.vgg16(pretrained=True).features):
if isinstance(layer, torch.nn.Conv2d):
self.features[i].weight.data = layer.weight.data
self.features[i].bias.data = layer.bias.data
def forward(self, x):
##return list of feature map at different size
features = []
for i, layer in enumerate(self.features):
layer.register_backward_hook(printgradnorm)
if(i in self.select ):
x = layer(x)
features.append(x)
else:
x = layer(x)
for i in self.deconv1:
i.register_backward_hook(printgradnorm)
for i in self.deconv2:
i.register_backward_hook(printgradnorm)
for i in self.deconv3:
i.register_backward_hook(printgradnorm)
self.final_attention_pred[0].register_backward_hook(printgradnorm)
saliency = []
m = nn.Sigmoid()
m1 = nn.Sigmoid()
m2 = nn.Sigmoid()
m3 = nn.Sigmoid()
m.register_backward_hook(printgradnorm)
attentionmap1 = self.deconv1(features[0])[:, :, 38:262, 38:262]
attentionmap1 = attentionmap1.expand(1, 3, 224, 224)
attentionmap2 = self.deconv2(features[1])[:, :, 38:262, 38:262]
attentionmap2 = attentionmap2.expand(1, 3, 224, 224)
attentionmap3 = self.deconv3(features[2])[:, :, 38:262, 38:262]
attentionmap3 = attentionmap3.expand(1, 3, 224, 224)
saliency.append(m(attentionmap1))
display_image(saliency[0].data.cpu())
saliency.append(m1(attentionmap2))
#display_image(saliency[0].data.cpu())
saliency.append(m2(attentionmap3))
#display_image(saliency[0].data.cpu())
output_data = torch.cat(saliency,1)
output = m3(self.final_attention_pred(output_data))
return output