Hello,
I was experimenting with Torchscript and I seem to be getting different outputs in my Python code versus my C++ code. I am simply loading the ResNet18 model, and loading a sample image: https://raw.githubusercontent.com/pytorch/hub/master/dog.jpg
I exported the resnet18 model following these instructions: Loading a TorchScript Model in C++ — PyTorch Tutorials 2.2.0+cu121 documentation
I am running on Windows 10 64-bit. For the C++ environment, I am running on Microsoft Visual Studio 2019. I am running the debug build of libtorch 1.4.0 for Visual Studio. I believe this is running fine, as I am able to load models and tensors to put CPU and GPU.
I believe I have an issue with my C++ code, but I am not sure where I have the error. Below is my code along with the outputs I get.
Python Code:
import torch
import torchvision.models as models
import urllib.request
from PIL import Image
from torchvision import transforms
def norm_chan(chan, mean, std):
b = (chan - mean) / std
return b
# Load resnet18 model
model = models.resnet18(pretrained = True)
# Download an example image from the pytorch website
url, filename = ("https://github.com/pytorch/hub/raw/master/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
import numpy as np
input_tensor_numpy = input_tensor.numpy()
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
import numpy as np
print()
output_cpu = output[0].cpu()
output_numpy = output_cpu.numpy()
print(output_numpy[0:9])
C++ code:
#include <torch/script.h>
#include <torch/torch.h>
#include <ATen/Tensor.h>
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <iostream>
#include <memory>
int main(int argc, const char* argv[]) {
// Load up GPU stuff
torch::DeviceType device_type;
if (torch::cuda::is_available()) {
std::cout << "CUDA available! Training on GPU." << std::endl;
device_type = torch::kCUDA;
}
else {
std::cout << "Training on CPU." << std::endl;
device_type = torch::kCPU;
}
torch::Device device(device_type);
torch::jit::script::Module module;
std::cout << "Attempting to load resnet model.." << std::endl;
try {
// Deserialize the ScriptModule from a file using torch::jit::load().
module = torch::jit::load("C:\\PyTorchPictureTest\\Model\\traced_resnet_model.pt");
std::cout << "Successfully loaded resnet model" << std::endl;
module.to(at::kCUDA);
std::cout << "Moved model to gpu" << std::endl;
// load image and transform
cv::Mat image;
image = cv::imread("C:\\PyTorchPictureTest\\dog.jpg", 1);
cv::cvtColor(image, image, 4); //had to change this part of the code because the cvtColor Enums did not seem to be working
cv::Mat img_float;
image.convertTo(img_float, CV_32F, 1.0 / 255);
cv::resize(img_float, img_float, cv::Size(224, 224));
auto img_tensor = torch::from_blob(img_float.data, { 1, 224, 224, 3 }).to(torch::kCUDA);
img_tensor = img_tensor.permute({ 0, 3, 1, 2 });
img_tensor[0][0] = img_tensor[0][0].sub(0.485).div(0.229);
img_tensor[0][1] = img_tensor[0][1].sub(0.456).div(0.224);
img_tensor[0][2] = img_tensor[0][2].sub(0.406).div(0.225);
auto img_var = torch::autograd::make_variable(img_tensor, false);
std::vector<torch::jit::IValue> inputs;
inputs.push_back(img_var);
torch::Tensor out_tensor = module.forward(inputs).toTensor();
std::cout << out_tensor.slice(1, 0, 10) << '\n';
}
catch (const c10::Error & e) {
std::cerr << "error loading the model\n";
return -1;
}
std::cout << "ok\n";
}
Output in Python:
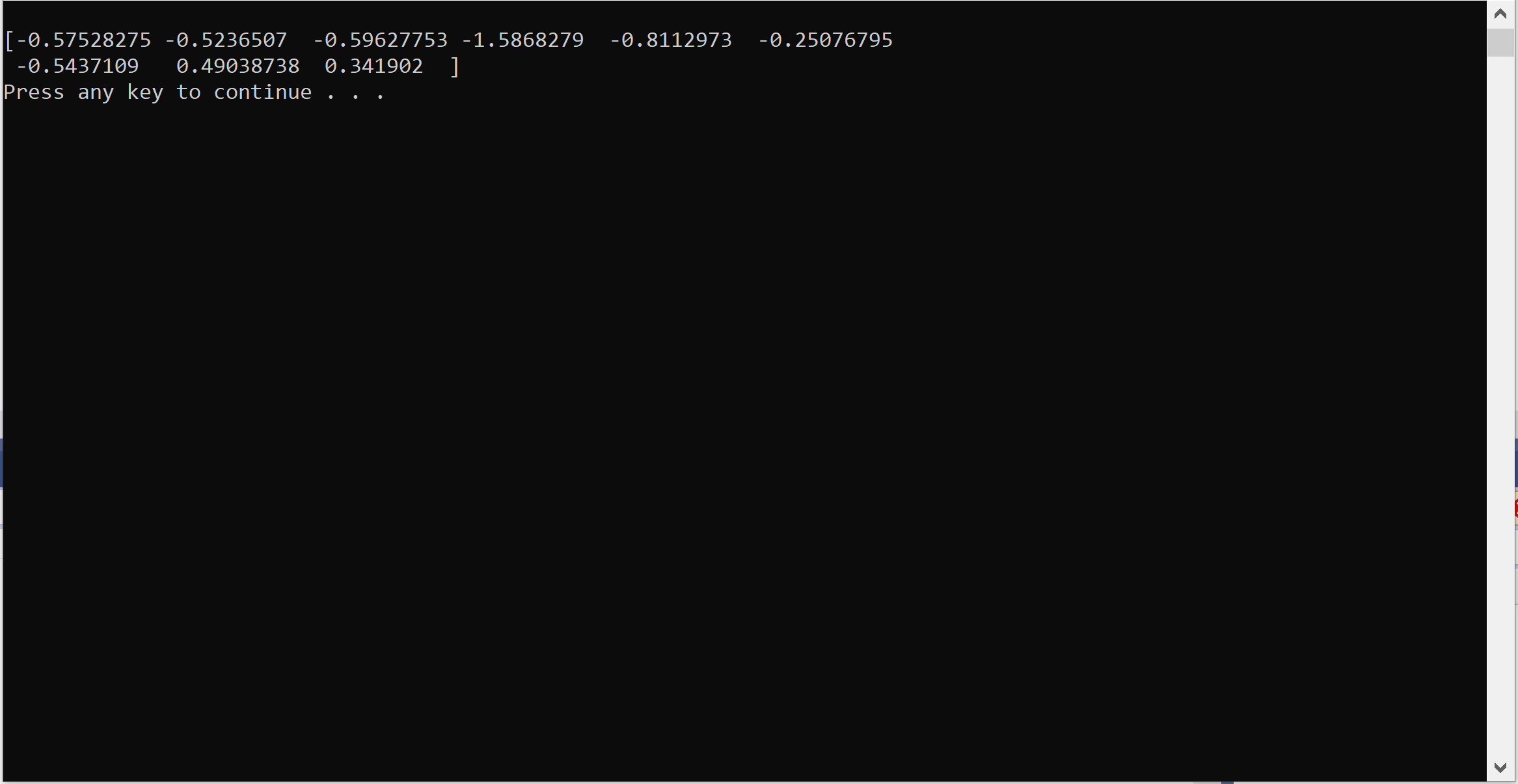
Output from C++:

{kind=link}
I would appreciate any insight on this. Thanks in advance.