I was usning the following architecture for training my model:
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(9, 27, kernel_size=3, stride=2, padding=0)
self.conv2 = nn.Conv2d(27, 54, kernel_size=5, stride=1, padding=0)
self.conv3 = nn.Conv2d(54, 64, kernel_size=6, stride=1, padding=1)
self.pool1 = nn.MaxPool2d((2,2))
self.conv4 = nn.Conv2d(64, 128, kernel_size=3,stride=1,padding=1)
self.conv5 = nn.Conv2d(128, 128, kernel_size=5,stride=2,padding=0)
self.pool2 = nn.MaxPool2d((2,2))
self.conv6 = nn.Conv2d(128, 64, kernel_size=3,stride=1,padding=0)
self.flat = nn.Flatten()
self.fc1 = nn.Linear(8704,512)
self.fc2 = nn.Linear(512,4)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = self.pool1(x)
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = self.pool2(x)
x = F.relu(self.conv6(x))
x = self.flat(x)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
and was getting the following output on test set after training:
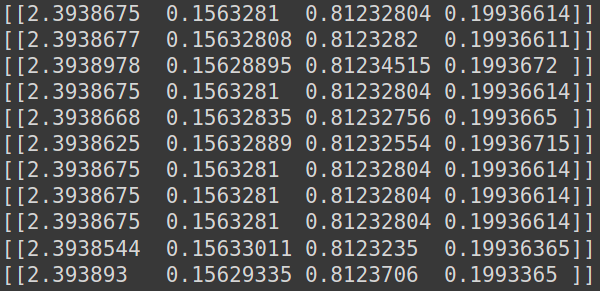
This is not a good prediction, since all the values are same.
But as soon as I use sequential class, with same architecture:
model = torch.nn.Sequential(
torch.nn.Conv2d(9, 27, kernel_size=3, stride=2, padding=0),
torch.nn.ReLU(),
torch.nn.Conv2d(27, 54, kernel_size=5, stride=1, padding=0),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, 2),
torch.nn.Conv2d(54, 64, kernel_size=6, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, 2),
torch.nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=0),
torch.nn.ReLU(),
torch.nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=0),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, 2),
torch.nn.Flatten(),
torch.nn.Linear(1024,512),
torch.nn.ReLU(),
torch.nn.Linear(512,4),
).to(device)
the output on test set after training:
[[3.2822053 1.3632872 2.3443744 0.00434288]]
[[ 2.5153766 0.00517752 -0.07172447 -0.04718025]]
[[ 7.12903 0.08480635 2.745857 -0.22266215]]
[[ 5.4862814 0.20487629 2.6381128 -0.03355677]]
[[0.766669 1.0363022 0.2687085 1.1925063]]
[[ 2.292058 0.2214803 2.2952085 -0.1321438]]
[[ 2.5587654 2.8598957 0.08964756 -0.16361943]]
[[ 1.3778323 -0.03345449 2.2093198 -0.11323967]]
[[ 2.2494226e+00 3.7341796e-02 -1.9486643e-02 -2.0913649e-03]]
[[-0.2568683 -0.16061799 0.03884238 2.7568922 ]]
[[ 2.6535883 0.06700002 0.12966754 -0.04277533]]
[[ 1.8448929 0.02760721 0.17743263 -0.07103067]]
I am not able to understand why this is happening since there shouldn’t be any difference between these two methods. I have tried with different architecture as well but the Sequential class was able to perform well on my training dataset while the conventional method was always just messing up.