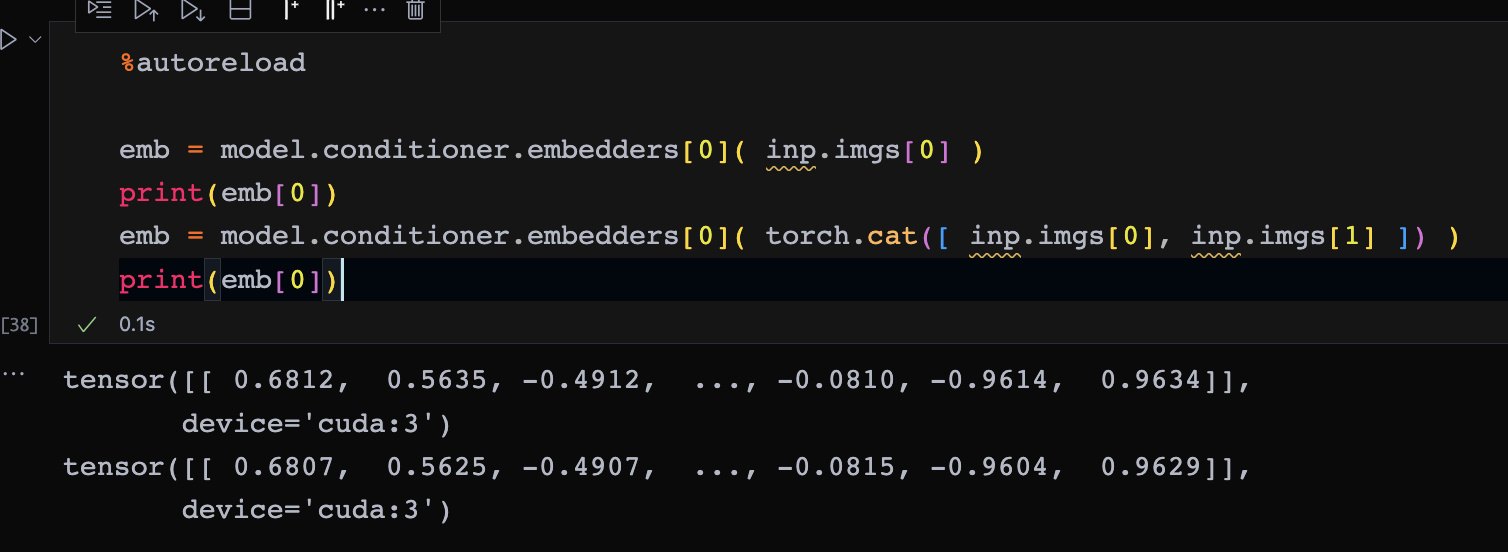
I boiled down my issue to a very simple example. This network produces different values (by a small decimal) based on the batch size. Note that the values remain consistent regardless of batch size when using CPU as the device (also, is it normal that the output between using CPU and cuda is different?).
import torch
import torch.nn as nn
import numpy as np
device = torch.device('cuda:0')
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(38, 256), nn.ReLU(),
nn.Linear(256, 96), nn.ReLU(),
nn.Linear(96, 64)
)
def forward(self, x):
out = self.fc(x)
return out.squeeze()
data = []
nr_features = 38
batch_size = 2
for i in range(batch_size):
datapoint = []
for j in range(nr_features):
datapoint.append(0.1)
data.append(datapoint)
data = torch.tensor(np.array(data)).float()
data = data.to(device)
torch.manual_seed(10)
model = Net()
model.to(device)
model.eval()
with torch.no_grad():
print(model(data)[0])
We used batch_size = 2 which prints the following:
tensor([-1.0196e-01, -4.0992e-03, -2.4501e-02, 2.7438e-02, -5.2672e-02,
-1.3104e-02, -8.8756e-02, -9.2451e-04, 1.2064e-02, -1.5039e-02,
4.3409e-02, 5.0925e-05, -3.3305e-02, 8.6518e-02, 6.3065e-02,
-6.5984e-02, -4.8023e-02, -5.3082e-02, -2.2278e-02, 8.6566e-02,
7.1233e-02, -4.8462e-03, 5.7919e-03, 1.4048e-01, 2.6209e-02,
-6.4638e-02, 1.5295e-02, 3.4366e-02, -6.0082e-03, 2.2381e-02,
1.1678e-02, -9.3038e-03, 1.0102e-01, 3.3924e-02, 4.5724e-02,
8.1887e-02, 4.6533e-03, 1.1872e-01, -1.5417e-02, -4.6537e-02,
8.4816e-02, -2.0553e-02, 1.8199e-02, 7.9428e-02, 1.6323e-02,
-1.2300e-02, -3.0991e-02, -1.0930e-02, -1.1830e-01, 1.3081e-01,
-1.4709e-02, -4.3337e-03, 6.4821e-02, 8.3538e-02, 6.3237e-02,
2.6764e-02, 1.1271e-02, 1.0993e-02, -2.3339e-02, 7.9234e-02,
-2.5017e-02, -5.9334e-02, 1.2681e-01, 5.2663e-02], device='cuda:0')
Now, if we set batch_size = 1024, the printed values are slightly different:
tensor([-1.0196e-01, -4.0855e-03, -2.4509e-02, 2.7435e-02, -5.2668e-02,
-1.3112e-02, -8.8748e-02, -9.1917e-04, 1.2068e-02, -1.5040e-02,
4.3407e-02, 5.9143e-05, -3.3300e-02, 8.6515e-02, 6.3070e-02,
-6.5981e-02, -4.8025e-02, -5.3084e-02, -2.2279e-02, 8.6570e-02,
7.1227e-02, -4.8462e-03, 5.7977e-03, 1.4048e-01, 2.6217e-02,
-6.4637e-02, 1.5298e-02, 3.4358e-02, -6.0073e-03, 2.2382e-02,
1.1673e-02, -9.3165e-03, 1.0103e-01, 3.3919e-02, 4.5729e-02,
8.1896e-02, 4.6527e-03, 1.1873e-01, -1.5428e-02, -4.6541e-02,
8.4820e-02, -2.0548e-02, 1.8202e-02, 7.9432e-02, 1.6322e-02,
-1.2294e-02, -3.0990e-02, -1.0929e-02, -1.1830e-01, 1.3081e-01,
-1.4717e-02, -4.3397e-03, 6.4816e-02, 8.3547e-02, 6.3231e-02,
2.6767e-02, 1.1276e-02, 1.1000e-02, -2.3333e-02, 7.9229e-02,
-2.5015e-02, -5.9328e-02, 1.2680e-01, 5.2660e-02], device='cuda:0')
What’s going on here and how can I reach deterministic outputs on cuda regardless of batch size?
Edit: It turns out that it happens with CPU as well, but seems to be more rare.