Hi, I trained a model, and want to use it to predict in a eval and no_grad model. Strangely, I got different results if I feed the same data to the model twice. Here is the code snipper:
with torch.no_grad():
for data in generator:
left = data['left']
right = data['right']
print('is training': self.model.training)
data1 = self.model(left, right)
data2 = self.model(left, right)
data2 = self.predict(data2)[0]
print(abs((data1-data2) >= 0.00001).double().sum())
and the output is like:
is training: False
tensor(10878., device=‘cuda:0’, dtype=torch.float64)
Small numerical mismatches are expected due to the limited numerical precision.
In your code it also seems the abs should be applied on the subtraction, not the comparison, so you might want to fix it.
Hi, ptrblck
Thank you for your time.
Yes, you are right, the abs should be applied on the subtraction.
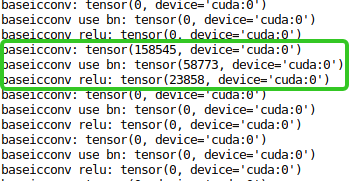
I traced the code and find that the difference came from the ConvTransposed2d module:
and the output looks like:
baseicconv: tensor(158545, device=‘cuda:0’)
If, as you said, the small numerical mismatches are expected, it should be always non-zero. However, as far as I know, the difference happens occasionaly:
PS: I found when set the batch-size to 1, there is no such a problem.
Hello, ptrblck. If I understand correctly, the output has a small numerical mismatch for the same input under the eval and no_grad model. But I don’t understand why the limited numerical precision will lead to this phenomenon. From my understanding, the calculation will keep the same decimal part for the same input if it is out of limited precision. Can you give a detailed explanation about this? Is there any other way to avoid this?