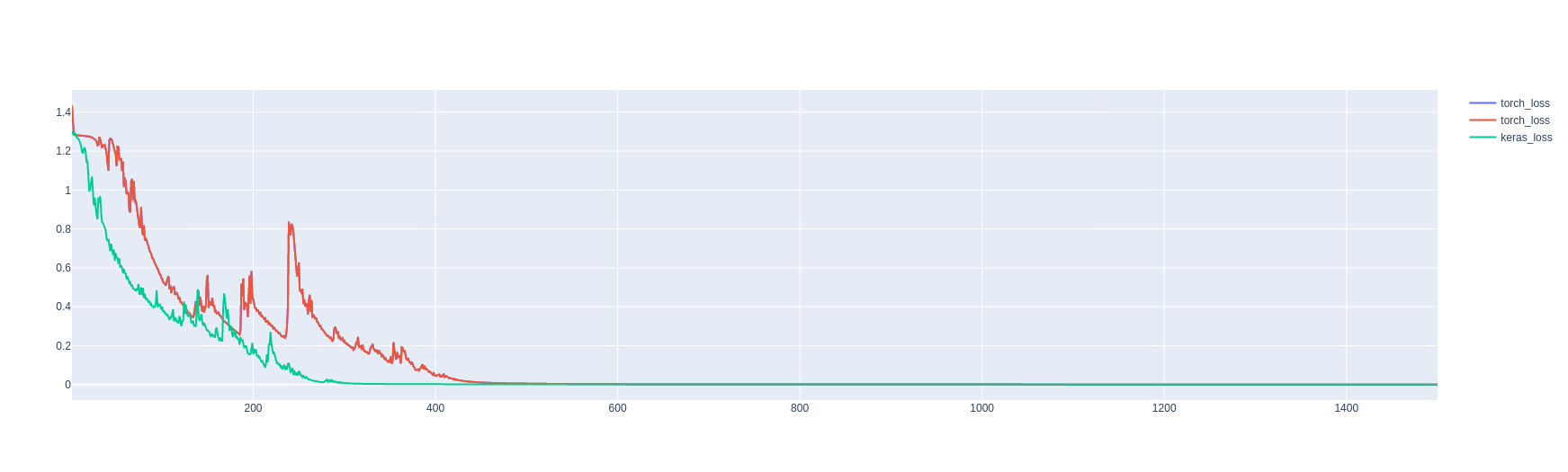
Hello everyone! I’m trying to implement my Keras/TF model in PyTorch. The model is a simple conv3d. Both models are running on CPU. So what am I doing wrong? Because the loss at any step (training, validation, test) are totally different between Pytorch and Keras.
[Keras]
epochs = 10
used_samples = 100
batch_size=10
validation_split = 0.2
with h5py.File(DATASET_FILE) as f:
real_tese = f['real'][...]
pred_tese = f['pred'][...]
pred = pred_tese[:used_samples]
real = real_tese[:used_samples]
if (validation_split):
split = int(pred.shape[0] * (1. - validation_split))
X_val = pred[split:]
y_val = real[split:]
X_train = pred[:split]
y_train = real[:split]
X_test = pred_tese[used_samples:-1]
y_test = real_tese[used_samples:-1]
seq = Sequential()
seq.add(Conv3D(filters=1, kernel_size=(3,3,3), padding='same',
data_format='channels_last'))
seq.compile(loss='mae', optimizer='rmsprop')
seq.fit(X_train, y_train, batch_size=batch_size, epochs=epochs,
validation_data=(X_val, y_val), shuffle=False)
scores = seq.evaluate(X_test, y_test)
[PyTorch]
epochs = 10
used_samples = 100
batch_size=10
validation_split=0.2
class H5Dataset(Dataset):
def __init__(self, file_path, samples, validation_split=0, isValidation=False):
super(H5Dataset, self).__init__()
h5_file = h5py.File(file_path,'r')
pred = h5_file.get('pred')[...]
real = h5_file.get('real')[...]
numpy_pred = pred[:samples]
numpy_real = real[:samples]
if (validation_split):
split = int(numpy_pred.shape[0] * (1. - validation_split))
if(isValidation):
numpy_pred = numpy_pred[split:]
numpy_real = numpy_real[split:]
else:
numpy_pred = numpy_pred[:split]
numpy_real = numpy_real[:split]
if (isTest):
numpy_pred = pred[samples:-1]
numpy_real = real[samples:-1]
self.X = torch.from_numpy(numpy_pred).float().permute(0, 4, 1, 2, 3)
self.y = torch.from_numpy(numpy_real).float().permute(0, 4, 1, 2, 3)
del pred; del real; del numpy_pred; del numpy_real
def __getitem__(self, index):
return (self.X[index,:,:,:,:], self.y[index,:,:,:,:])
def __len__(self):
return self.X.shape[0]
(...)
params = {'shuffle': False, 'num_workers': 1}
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, **params)
val_loader = DataLoader(dataset=val_dataset, batch_size=batch_size, **params)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, **params)
class Conv.Module):
def __init__(self):
super(Conv, self).__init__()
self.conv = nn.Conv3d(in_channels=5, out_channels=1, kernel_size=(3,3,3),
padding=(1,1,1))
def forward(self, x):
out = self.conv(x)
return out
model = Conv().to(device)
criterion = nn.L1Loss()
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.001, alpha=0.9, eps=1e-6)
def train(model, loss_fn, dataloader, device):
model.train()
epoch_loss = 0.0
for i, (feature, target) in enumerate(dataloader):
feature, target = feature.to(device), target.to(device)
optimizer.zero_grad()
output = model(feature)
loss = loss_fn(output, target)
epoch_loss += loss.item()
loss.backward()
optimizer.step()
return epoch_loss/len(dataloader)
def evaluate(model, loss_fn, dataloader, device):
model.eval()
epoch_loss = 0.0
with torch.no_grad():
for feature, target in dataloader:
feature, target = feature.to(device), target.to(device)
output = model(feature)
loss = loss_fn(output, target)
epoch_loss += loss.item()
return epoch_loss/len(dataloader)
(...)
Results example:
[Keras]
Train on 80 samples, validate on 20 samples
Epoch 1/10 - loss: 32.1959 - val_loss: 9.7006
Epoch 2/10 - loss: 4.9858 - val_loss: 3.6706
Epoch 3/10 - loss: 3.8655 - val_loss: 3.6865
(...)
Epoch 8/10 - loss: 3.8235 - val_loss: 3.5489
Epoch 9/10 - loss: 3.7683 - val_loss: 3.4872
Epoch 10/10 - loss: 3.7115 - val_loss: 3.4237
Test_loss: 3.65
[PyTorch]
Train on 80 samples, validate on 20 samples
Epoch: 1/10 - loss: 16.0479 - val_loss: 3.7342
Epoch: 2/10 - loss: 3.7276 - val_loss: 4.0231
Epoch: 3/10 - loss: 3.8023 - val_loss: 4.0526
(...)
Epoch: 8/10 - loss: 3.5709 - val_loss: 3.8442
Epoch: 9/10 - loss: 3.5239 - val_loss: 3.7991
Epoch: 10/10 - loss: 3.4762 - val_loss: 3.7512
Test_loss: 3.39
I know the PyTorch data format is “channel first” and Keras is “channel last”, and that’s the reason I used permute().
Thanks for the help!