Having trouble to replicate model output after save>load.
It’s a triplet model with ResNet50 as an inner model.
Went both ways at the same time: saved state_dict of both models + optimizer vs saving model.cpu() itself.
After calculating output tensor on single input right before saving model and after loading, I have different tensors before and after, yet same if I load state_dict vs model as a whole.
Visualization (TSNE) shows that model is completely lost any sense of understanding what’s going on
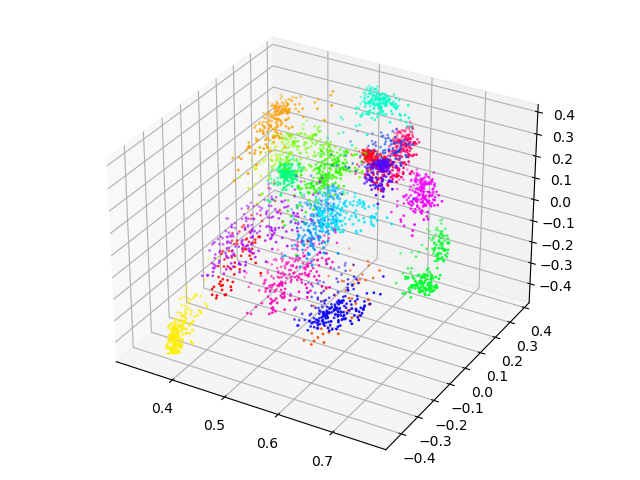
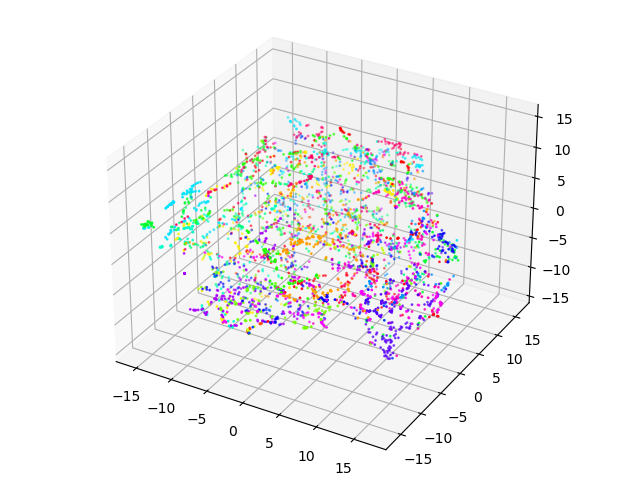
modelFilename = "modelResNet.mdl"
model = torch.load(modelFilename)
model.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9)
model.eval()
Am I missing something? Is it something related to zero grad?