Hi, I am measuring the total number of Floating point operations and also the layer-wise and operation-wise runtime of Resnet18 using a tool.
The format of the output is as follows :
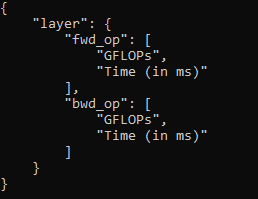
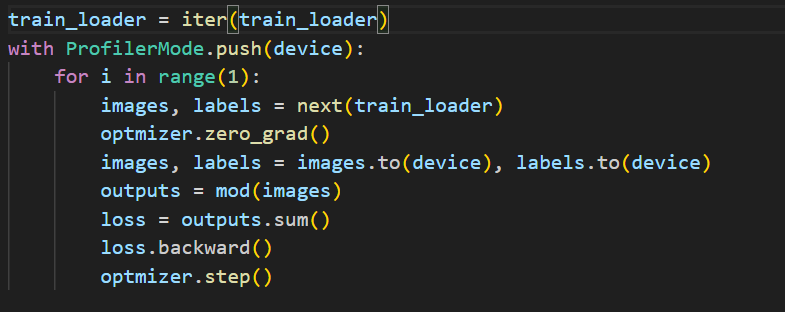
The core operation of the tool is as follows :
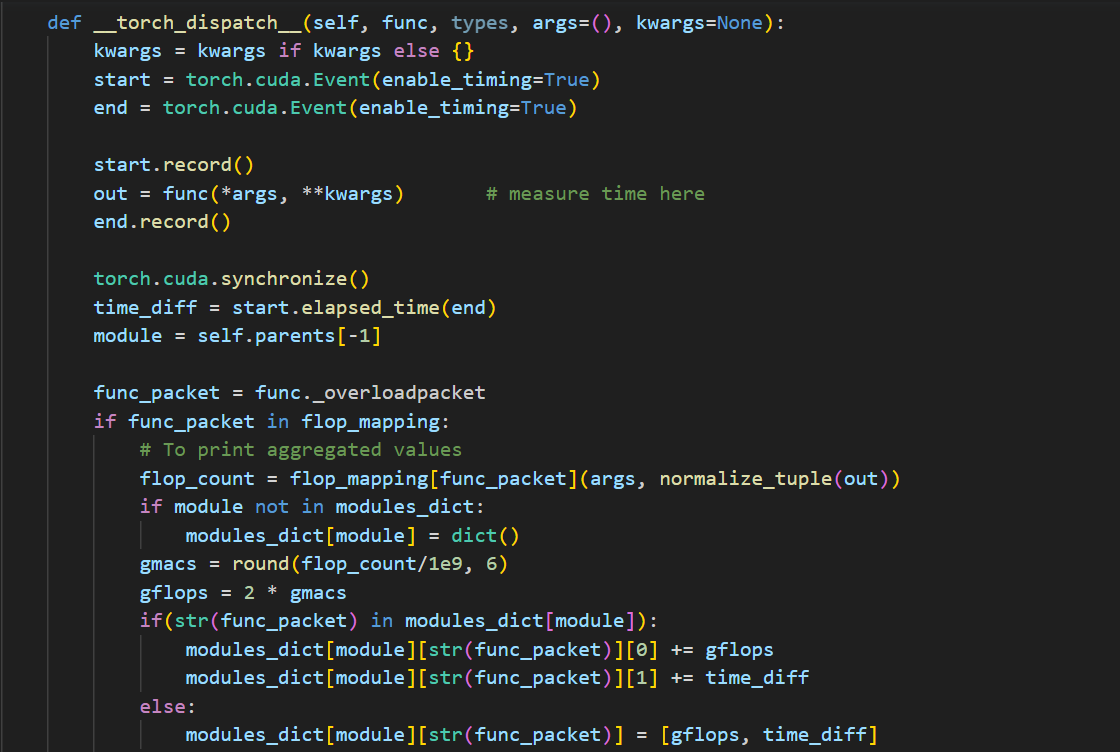
Torch dispatcher intercepts the operation calls - like aten.conv and aten.conv_backward and I have used a custom function that calculates FLOPs based on the type of the operator and dimensions of the operator. I also profile the per-operator run time for all the layers using torch.cuda.Event and append both the FLOPs and runtime of every Conv and FCL into a dictionary.
I have done a warmup for 30 iterations and then have profiled for the following variants (all with batch_size as 1)
- single randn input
- single image input (from imagenet dataset)
- 100 images input
Output when Resnet18 is fed with a single input image from Imagenet is as follows :
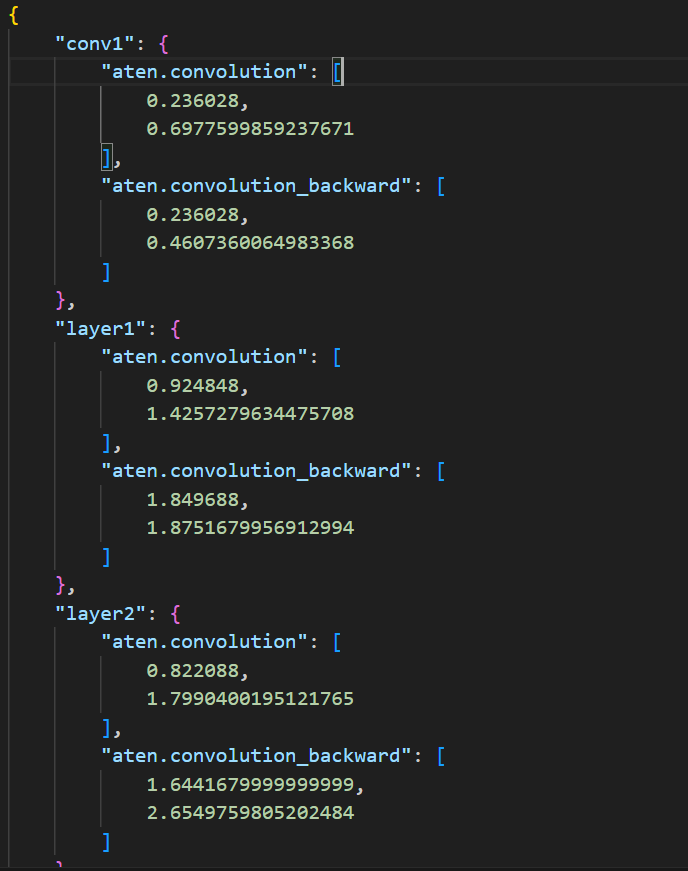
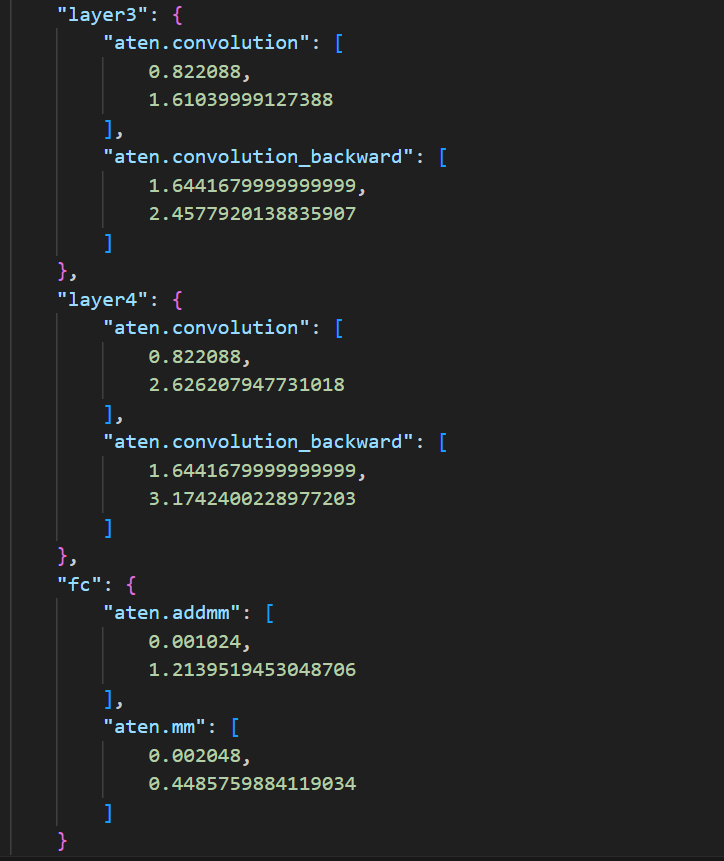
And the main driver code is as follows :
For all the input variants, I’m facing the below issues :
-
Unusual increase in runtime for operations in different layers when the FLOPs are same (Ex for layer4 the runtime is greater than other layers)
-
In some cases, runtime for an operation for Forward pass takes more time than that of Backward pass (Ex for conv1 layer in the above output)
It would be great if someone can reason why there is variation in runtime even when FLOPs are the same