Hi,
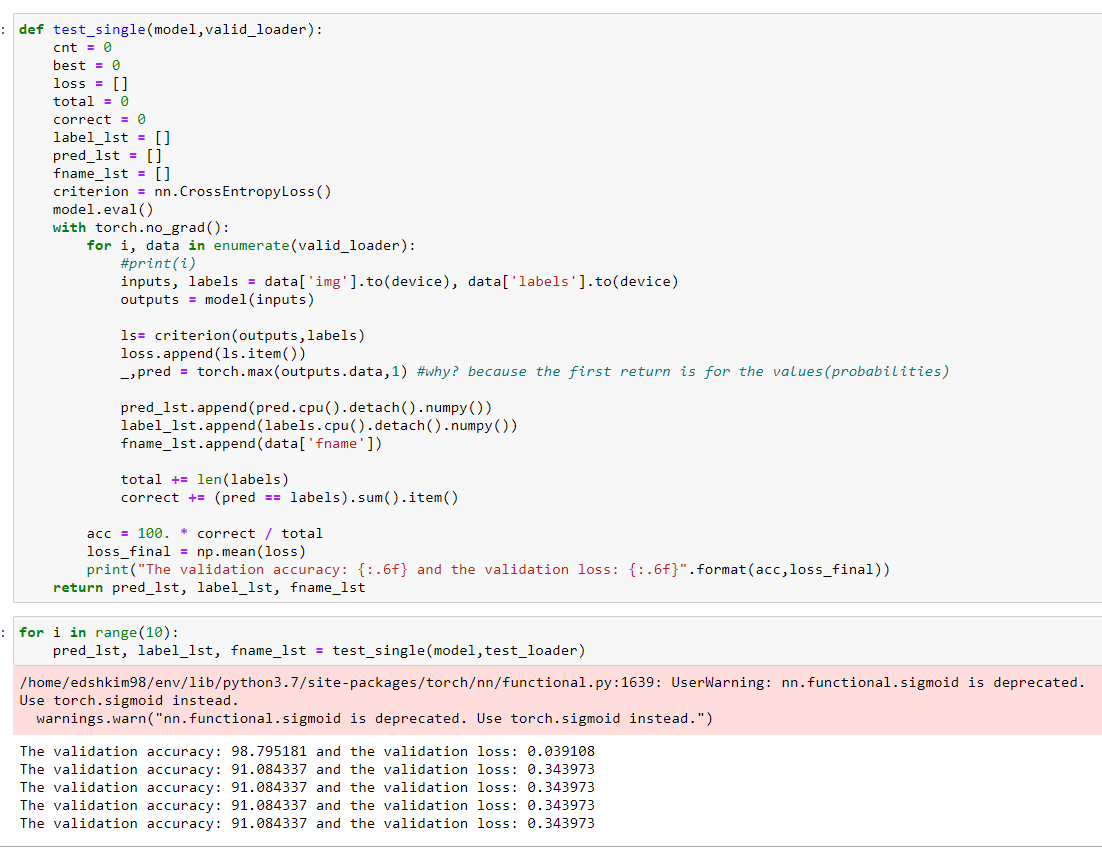
I have a pre-trained model and whenever I try to test my model on the same test data, I get different accuracy and loss every time.
For example, for my first try, I get 98% in test accuracy, but then when I re-test the model on the exact same test data loader, I now get 91%.
Since the model weights are fixed during inference, there should be no such thing as randomness.
What could have gone wrong here?
It seems as if the very first iteration differs from the subsequent ones.
Could you post the model definition or an executable code snippet, which would reproduce this issue, please?
The only difference is that I did not open the image file during initialization, but opened it during getitem function. However, I don’t see the difference. Do you know what is the difference between opening an image file using PIL in init and getitem?
There shouldn’t be any difference besides the memory usage, which would be higher when you are preloading all images.
Besides that, your code is unfortunately not executable, so that I cannot run or debug it, but good to hear it’s working now.