Hello everyone, I’m trying to replicate some basic linear regression results from sci-kit learn’s LASSO implementation into pyTorch and finding that the solution quality is nowhere near as good. I’ve tried this two separate ways, first by explicitly adding a penalty to the loss function, similar to what is described here: python - Pytorch: how to add L1 regularizer to activations? - Stack Overflow
The second way I’ve tried is using AdamW and effectively treating lambda (weight decay) the same way it’s used in LASSO (creating curves of train and cross-validation error as a function of lambda).
In both cases, I get sub-optimal results vs. sci-kit learn (i.e. the validation and test set objective functions are higher). Also, I get a substantial level of noise in the training, even with a lower learning rate (1.0e-4) and a fairly high weight decay:
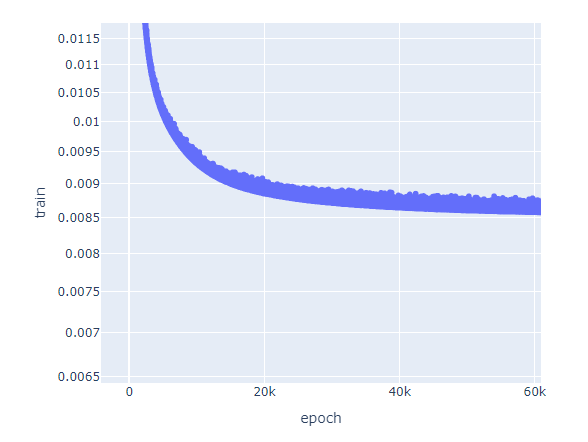
The obvious solution is to use sci-kit learn, but I’m trying both dense and LSTM models on the same datasets which show very similar issues, I thought it easiest to debug the linear model first. Thoughts?