for padding same i would do left = (kernel_size - 1) // 2 right = (kernel_size - 1) - left F.pad(x, (left,right)
however im unsure about the kernel size [m x 1] again . Would it for my example just be 3?
in pytorch conv1d dispatches to conv2d, adding a fake dimension, I guess in their framework something similar happens, or they have other reasons to unsqueeze input to 4d.
in pytorch conv1d dispatches to conv2d, adding a fake dimension, I guess in their framework something similar happens, or they have other reasons to unsqueeze input to 4d.
Oh I understand.
I didn’t say to use 3 with conv2d
Sry if I did understand you wrong. But what did you mean?
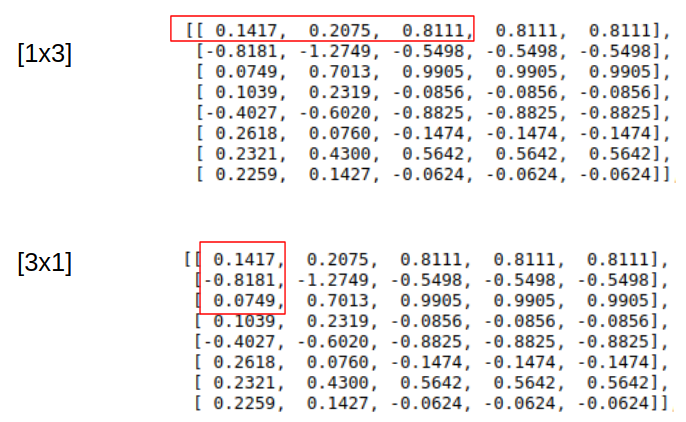
As I understand it the [1x3] or kernel size 3 for conv1d with dilation learns the causality of each channel. However, [3x1] learns the correlation between these channels.
But I’m unsure how to express that [3x1] filter with conv1d.
Kernel size is not about channels, it is a “window” size in spatial/time dimension, 1d window for 3d input, 2d for 4d input. Tensor format is (batch, channels, time), with kernel_size 3 you’re aggregating 3 timesteps, while in_channels -> out_channels map is dense.
yes thats what I tried to visualize with the [1x3] red rectangle. a window of three time steps in the time dimension.
But what im trying to understand is the [3x1] window and how this is expressed with pytorch conv1d.
For the first picture, you’d normally get 8 channels x 3 timesteps windows, unless you use channel groups (groups=8 parameter would divide channels as 8/8).
There is no built-in support for uneven channel groups (e.g. 3/8 channels). You can implement that with masks (F.conv1d(input, weight*mask, …)), but it is a bit cumbersome.
@googlebot thanks for you help I think I understood it now…
so for the conv1d with kernel size 3 it is like this
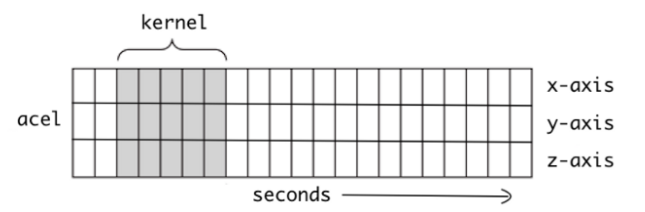
the filter with size 5 moving over the time steps. and depending on how “high” the next matrix should be the more filters we use. so for 8 output channels 8 filters etc.
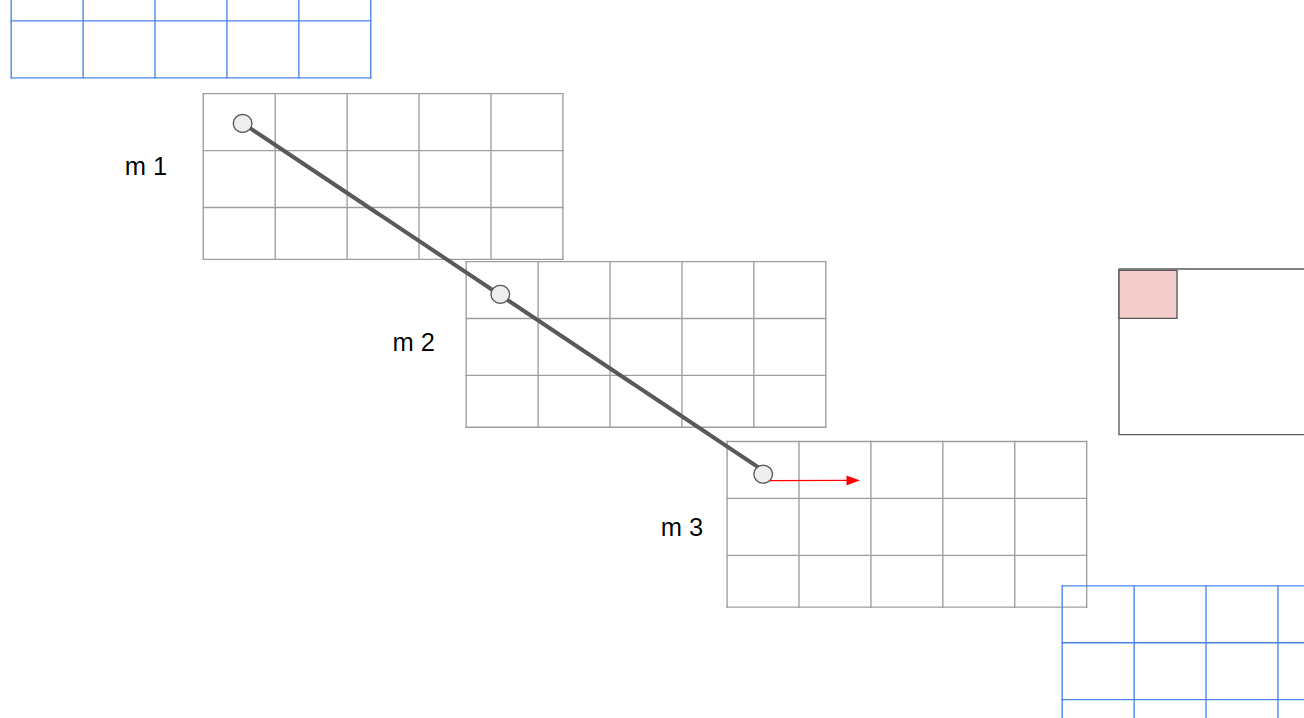
now I’m thinking of the correlation convolution. just imagine there would be 3 acel matrices of three different objects… like in the image below. with a [mx1] kernel I want to go over each input channel of the three elements. I would pad one matrix m0 and one m4 so that I would be able to get 3 output matrices.
so as in the picture. input would be (3,3,5) and a possible output (3,3,5). by that having 3 filters. I’m just unsure if this would be possible.
I was also considering to just “.transpose(0,2)” the matrix. so that the batch_size becomes the time steps and the time steps the batch size. and then use a regular conv1d with kernel size m the previously batch size and now time steps.
Hope I could make it somehow understandable. Do you think this would be possible without transposing?