Hello, I’m new to PyTorch and getting an error that I’m not sure how to fix. This occurred in a Convolutional Neural Network implementation. The error says:
“RuntimeError: Expected 4-dimensional input for 4-dimensional weight [16, 1, 5, 5], but got 3-dimensional input of size [5, 28, 28] instead”. I’ve provided a more detailed view of the code and error as an image at the bottom.
I understand that this error means I need to provide a 4-D input instead of a 3-D input somewhere, but I’m not sure where I am going wrong, what to change, or how to get the right dimensions. I understand the calculations relating to padding, convolutions, and strides, and I’m thinking the error probably has to do with how I formatted my data. This data came from a CSV file, with each row representing an image and a label. I transformed each row into a tuple of tensors, with the first element of the tuple as the image and the second element as the label. I put these tuples into a list, then convert the Dataset to a DataLoader. I’m using a batch size of 5.
I’ve included my code here below (as an image and pasted in too, not sure which is easier), any help/explanations/pointers are much appreciated. The steps I followed here are based on Udemy PyTorch course, Practical Deep Learning with Pytorch, which I modified for this new dataset. The dataset I’m using consists of 28x28 images with 24 possible class values (Sign Language MNIST | Kaggle), which I imported and transformed as described above:
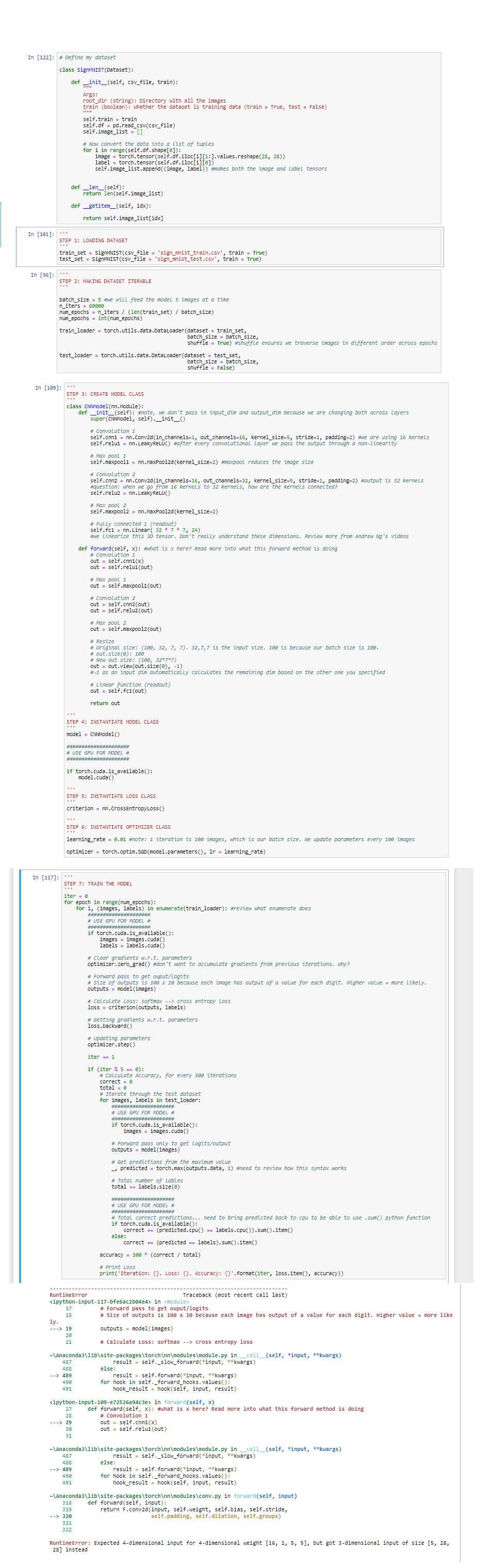
# Define my dataset
class SignMNIST(Dataset):
def __init__(self, csv_file, train):
"""
Args:
root_dir (string): Directory with all the images
train (boolean): Whether the dataset is training data (train = True, test = False)
"""
self.train = train
self.df = pd.read_csv(csv_file)
self.image_list = []
# Now convert the data into a list of tuples
for i in range(self.df.shape[0]):
image = torch.tensor(self.df.iloc[i][1:].values.reshape(28, 28))
label = torch.tensor(self.df.iloc[i][0])
self.image_list.append((image, label)) #makes both the image and label tensors
def __len__(self):
return len(self.image_list)
def __getitem__(self, idx):
return self.image_list[idx]
'''
STEP 1: LOADING DATASET
'''
train_set = SignMNIST(csv_file = 'sign_mnist_train.csv', train = True)
test_set = SignMNIST(csv_file = 'sign_mnist_test.csv', train = True)
'''
STEP 2: MAKING DATASET ITERABLE
'''
batch_size = 5 #we will feed the model 5 images at a time
n_iters = 60000
num_epochs = n_iters / (len(train_set) / batch_size)
num_epochs = int(num_epochs)
train_loader = torch.utils.data.DataLoader(dataset = train_set,
batch_size = batch_size,
shuffle = True) #shuffle ensures we traverse images in different order across epochs
test_loader = torch.utils.data.DataLoader(dataset = test_set,
batch_size = batch_size,
shuffle = False)
'''
STEP 3: CREATE MODEL CLASS
'''
class CNNModel(nn.Module):
def __init__(self): #note, we don't pass in input_dim and output_dim because we are changing both across layers
super(CNNModel, self).__init__()
# Convolution 1
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2) #we are using 16 kernels
self.relu1 = nn.LeakyReLU() #after every convolutional layer we pass the output through a non-linearity
# Max pool 1
self.maxpool1 = nn.MaxPool2d(kernel_size=2) #maxpool reduces the image size
# Convolution 2
self.cnn2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2) #output is 32 kernels
#question: when we go from 16 kernels to 32 kernels, how are the kernels connected?
self.relu2 = nn.LeakyReLU()
# Max pool 2
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
# Fully connected 1 (readout)
self.fc1 = nn.Linear( 32 * 7 * 7, 24)
#we linearize this 3D tensor. Don't really understand these dimensions. Review more from Andrew Ng's videos
def forward(self, x): #what is x here? Read more into what this forward method is doing
# Convolution 1
out = self.cnn1(x)
out = self.relu1(out)
# Max pool 1
out = self.maxpool1(out)
# Convolution 2
out = self.cnn2(out)
out = self.relu2(out)
# Max pool 2
out = self.maxpool2(out)
# Resize
out = out.view(out.size(0), -1)
#-1 as an input dim automatically calculates the remaining dim based on the other one you specified
# Linear function (readout)
out = self.fc1(out)
return out
'''
STEP 4: INSTANTIATE MODEL CLASS
'''
model = CNNModel()
#####################
# USE GPU FOR MODEL #
#####################
if torch.cuda.is_available():
model.cuda()
'''
STEP 5: INSTANTIATE LOSS CLASS
'''
criterion = nn.CrossEntropyLoss()
'''
STEP 6: INSTANTIATE OPTIMIZER CLASS
'''
learning_rate = 0.01 #note: 1 iteration is 100 images, which is our batch size. We update parameters every 100 images
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
'''
STEP 7: TRAIN THE MODEL
'''
iter = 0
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader): #review what enumerate does
#####################
# USE GPU FOR MODEL #
#####################
if torch.cuda.is_available():
images = images.cuda()
labels = labels.cuda()
# Clear gradients w.r.t. parameters
optimizer.zero_grad() #don't want to accumulate gradients from previous iterations. Why?
# Forward pass to get ouput/logits
# Size of outputs is 100 x 10 because each image has output of a value for each digit. Higher value = more likely.
outputs = model(images)
# Calculate Loss: softmax --> cross entropy loss
loss = criterion(outputs, labels)
# Getting gradients w.r.t. parameters
loss.backward()
# Updating parameters
optimizer.step()
iter += 1
if (iter % 5 == 0):
# Calculate Accuracy, for every 500 iterations
correct = 0
total = 0
# Iterate through the test dataset
for images, labels in test_loader:
#####################
# USE GPU FOR MODEL #
#####################
if torch.cuda.is_available():
images = images.cuda()
# Forward pass only to get logits/output
outputs = model(images)
# Get predictions from the maximum value
_, predicted = torch.max(outputs.data, 1) #need to review how this syntax works
# Total number of lables
total += labels.size(0)
#####################
# USE GPU FOR MODEL #
#####################
# Total correct predictions... need to bring predicted back to cpu to be able to use .sum() python function
if torch.cuda.is_available():
correct += (predicted.cpu() == labels.cpu()).sum().item()
else:
correct += (predicted == labels).sum().item()
accuracy = 100 * (correct / total)
# Print Loss
print('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-117-bfe6ac2b04e4> in <module>
17 # Forward pass to get ouput/logits
18 # Size of outputs is 100 x 10 because each image has output of a value for each digit. Higher value = more likely.
---> 19 outputs = model(images)
20
21 # Calculate Loss: softmax --> cross entropy loss
~\Anaconda3\lib\site-packages\torch\nn\modules\module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
<ipython-input-109-e72526a94c3e> in forward(self, x)
27 def forward(self, x): #what is x here? Read more into what this forward method is doing
28 # Convolution 1
---> 29 out = self.cnn1(x)
30 out = self.relu1(out)
31
~\Anaconda3\lib\site-packages\torch\nn\modules\module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~\Anaconda3\lib\site-packages\torch\nn\modules\conv.py in forward(self, input)
318 def forward(self, input):
319 return F.conv2d(input, self.weight, self.bias, self.stride,
--> 320 self.padding, self.dilation, self.groups)
321
322
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [16, 1, 5, 5], but got 3-dimensional input of size [5, 28, 28] instead
