hey, I’m trying to resume training from a given checkpoint using pytorch CosineAnnealingLR scheduler.
let’s say I want to train a model for 100 epochs, but, for some reason, I had to stop training after epoch 45 but saved both the optimizer state and the scheduler state.
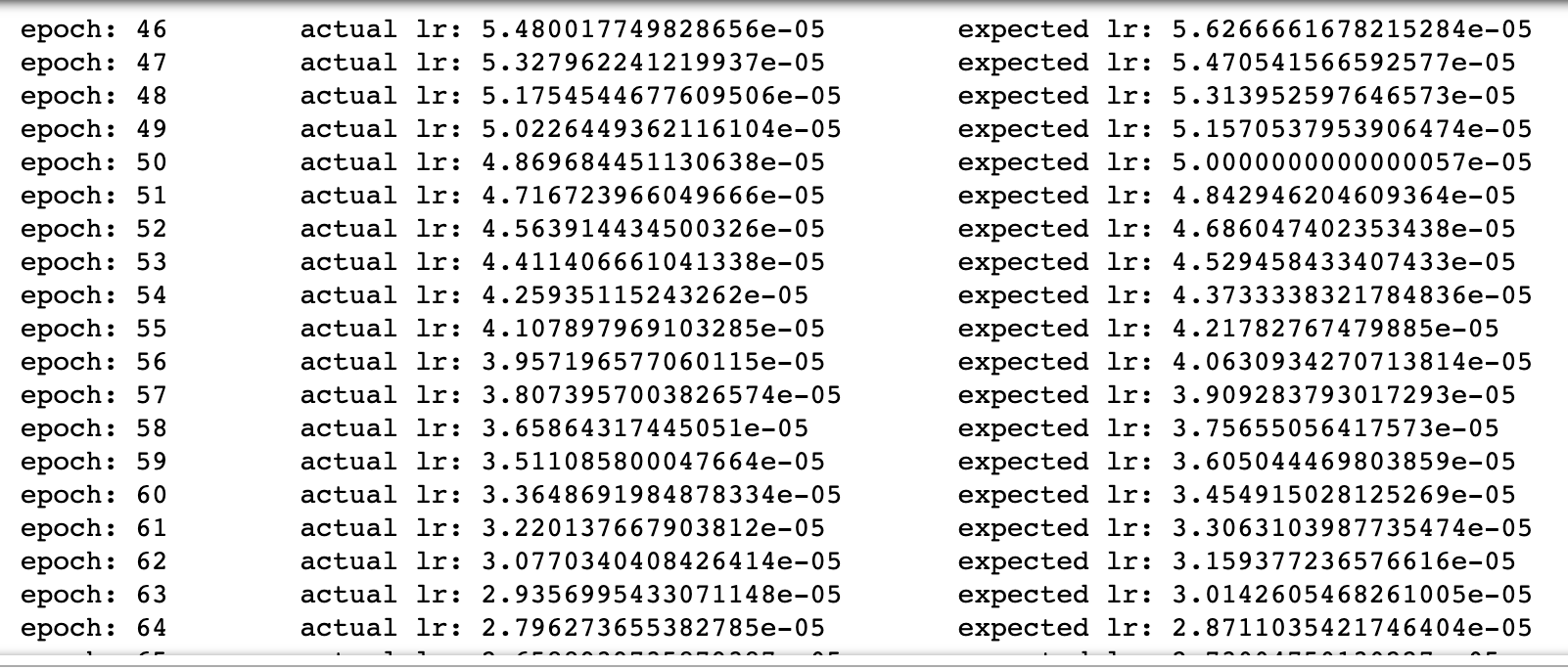
I want to resume training from epoch 46. I’ve followed what has previously been chatted on this forum to resume training from a given epoch, but when plotting learning rates values as a function of epochs, I get a discontinuity at epoch 46 (see figure below, plot on the left).
For comparison, I run the full 100 epochs and plotted the learning rate to show what the expected plot should look like (see figure below, plot in the center).
We can see both plots do not match when displaying them on the same figure (see figure below, plot on the right ; in green: expected plot ; in blue: plot with discontinuity)
Here is a snippet of the code I’ve used to resume training:
intial_epoch = 0
nepochs_first = 45
nepochs_total = 100
base_lr = 0.0001
optimizer_first = torch.optim.Adam(model.parameters(), lr=base_lr)
scheduler_first = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_first, T_max=nepochs_total, last_epoch=intial_epoch-1)
lr_first = []
for i in range(intial_epoch+1, nepochs_first+1):
scheduler_first.step()
lr_first.append(scheduler_first.get_last_lr()[-1])
optimizer_state, scheduler_state = optimizer_first.state_dict(), scheduler_first.state_dict()
optimizer = torch.optim.Adam(model.parameters(), lr=1)
# I deliberately set the initial lr to a different value than base_lr, and it should be overwritten when loading the state_dict
optimizer.load_state_dict(optimizer_state)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=nepochs_total, last_epoch=nepochs_first-1)
scheduler.load_state_dict(scheduler_state)
prev_epoch = scheduler_state['last_epoch']
lr = []
for i in range(prev_epoch+1, nepochs_total+1):
scheduler.step()
lr.append(scheduler.get_last_lr()[-1])
I’ve tried a bunch of things but I couldn’t manage to get over this discontinuity.
Thanks you for your help!