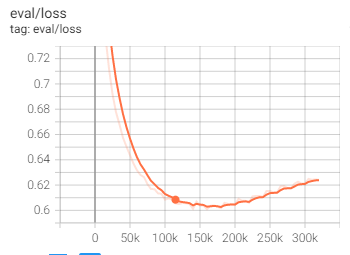
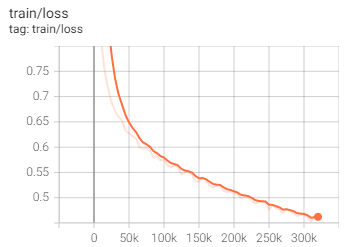
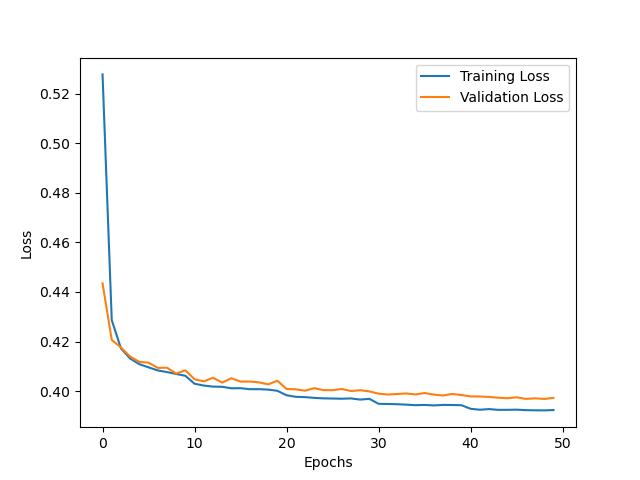
Hi @ptrblck , I hope you are well. sorry, I fine tunned the gpt -2. with batch size of 4 and lr=5g-5. the training and validation loss is as following. i believe that training is not converge still need more or get stuck in local minimal. but the validation loss increase. what is your idea? i think increase batch size is good to 8 or 16 because gpt is a big model. should I increase the lr as well? what do u think in total. many thanks
@ptrblck many thanks for your reply. Sorry, Regarding training loss I think it stuck in local minimal as well. Anyway, As I am fine tunning the gpt2 and it is a big model, there are some ways in my mind, changing the weight decay currently is 0.01 do u think i need make it smaller 0.001 ?? And another thing is adding more data. Or I can freez some layers in gpt2 and just fine tune some last layers not all. I am a bit concern about local minimal as well. Thanks for your idea.
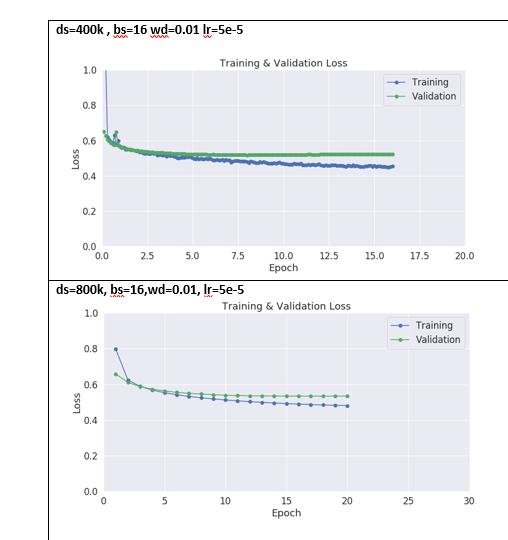
Hi @ptrblck , I hope you are well. sorry, I increased my data size to fine tunning the gpt from 400k to 800 k ( as discussed above). they are my graphs for comparison. do you think the model is converge or stuck in a local minimum? Validation loss didn’t start to increase, do you think it needs more epoch to be trained until validation loss start to increase? regarding the training loss is it stuck to the minimal? or it is good? is the model from the last epoch is the best since validation loss remain steady and didn’t increase? I really appreciate your help. I have a feeling that the training get stuck in a local minimal. is it good to freeze some layers and then fine tunning?