I seen many scripts that uses pre-trained models provided by Pytorch and follow along with the recommendation of normalising according to the mean and standard deviation of ImageNet.
I do not understand why is it not recommended by Pytorch to normalise according to individual datasets considering that the purpose of normalisation is to bring the dataset to a standard normal distribution to ease the optimization process (gradient descent)? This is especially true for the purpose of fine-tuning where every weight and bias parameters is being changed according to a new dataset.
If we use ImageNet normalisation on our own dataset, it will not bring the our dataset to a standard normal distribution. Wouldn’t the effect of normalisation (following ImageNet) be the same as literally just subtracting random numbers that we pick out of thin air (from the perspective of our own dataset)?
Could you post the link where it’s advised to use the ImageNet stats and not to calculate them from your dataset, please?
I would claim these stats work on “natural” images (or in other words ImageNet-like images) and could yield a good baseline. Your training might benefit from custom stats, but you would need to check if for your use case (and please update this thread in case you have some results).
In my experience your training might suffer, if you are using images from another domain (such as medical data), but it also depends on your use case and I don’t want to create a general assumption that it cannot work.
From link:
"
All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel
RGB images of shape (3 x H x W), where H and W are expected to be at least 224. The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225]. You can use the following transform to normalize:
There’s no mention about not calculating them from own dataset (I never said that).
This is where I am confused, I cannot figure out why would there be any potential benefit at all from the custom stat. What does ImageNet mean and standard deviation has anything to do with our own datasets ? The only exception I can think of is if someone is using the pre-trained model to improve the performance of the model on ImageNet itself. Given the diversity of ImageNet, our own data has to been equally diverse on similar categories to have any sort of use for the custom state.
This is just what I think, happy to discuss further.
Thanks for the link. I understand the part more as an explanation on how to use or fine-tune the pretrained model in order to get the same results. E.g. if you skip the normalization and just feed the raw ImageNet dataset into it, the performance will be worse.
As already said, you can calculate the custom stats and it would be interesting to see, if you are seeing any benefits. Reusing the ImageNet stats seems to work in practice for “a lot” of use cases but the “lot” depends on your research area (e.g. see the point about medical data from before).
The ImageNet dataset used to pretrain the torchvision models contains a variety of “natural” images from 1000 categories. If your custom image dataset contains similar images of e.g. dogs, cats, strawberries, etc. the same stats could work. Did you compute the stats from your images and compared them to the ImageNet ones? If so, how large was the difference?
I agree that if you skip normalisation (to normal distribution) and feed the raw ImageNet dataset, the performance will be worse for ImageNet but I am not too sure whether is that true for any other dataset.
(Test 1): To test the above.
(Test 2): To test the above. My theory is that the ImageNet stats is useless because even if the dataset consist of similar categories of images to ImageNet, the custom stats of ImageNet does not in any way correlate due to the fact that it has way more categories (ex: 3 same categories vs 997 categories that are non-existent in your own dataset).
I will figure out how to best verify the 2 tests, get back to this post when I have done so. Thank you for the reply, you are really active in this forum!
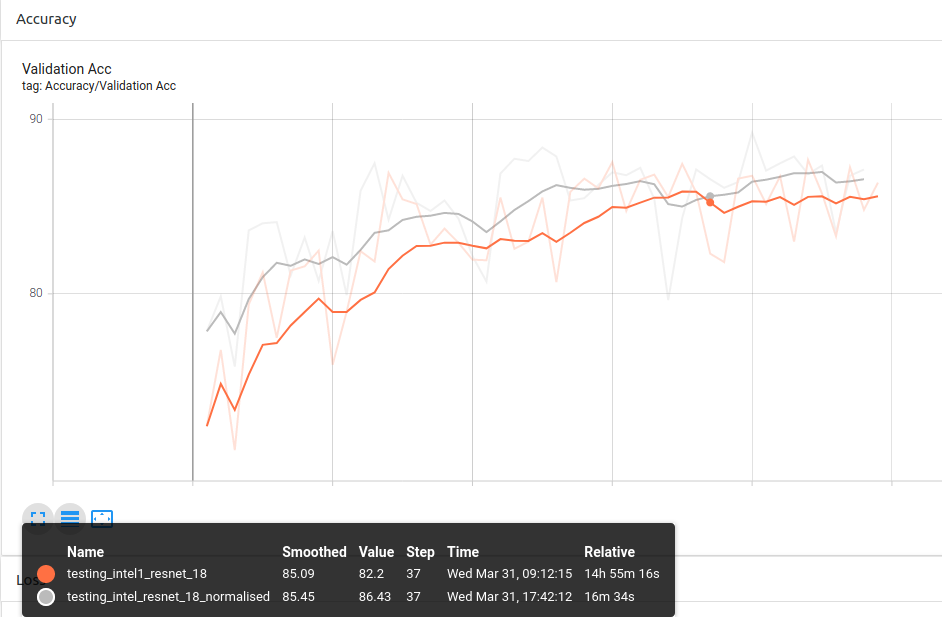
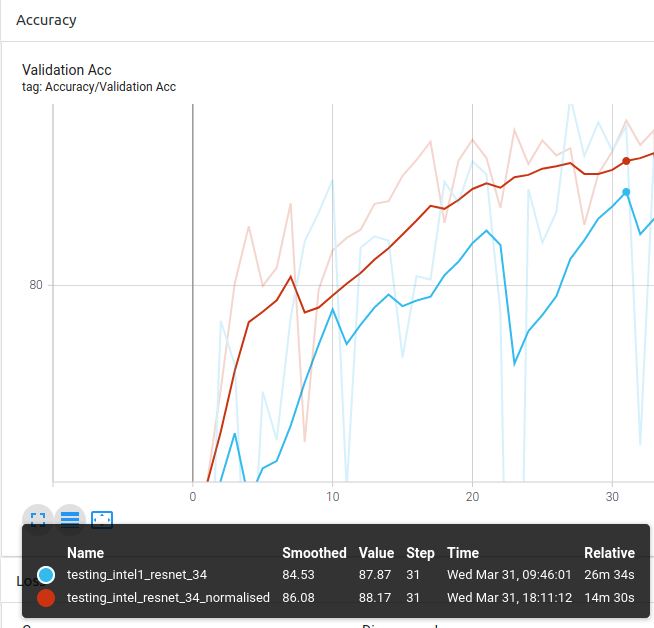
You can see the general trend being that the normalised experiments are slightly above the experiment without normalisation most of the epochs.
Conclusion 1: Using custom ImageNet stats for the pytorch pretrained models provides better results than without normalisation as it is trained on ImageNet.
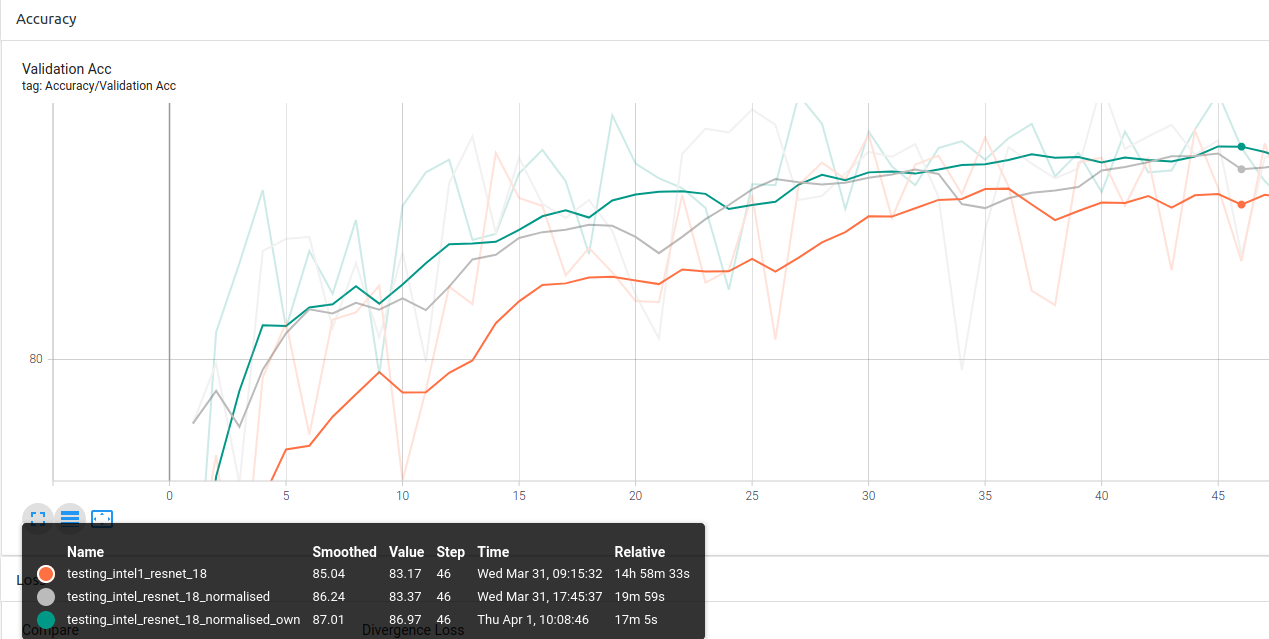
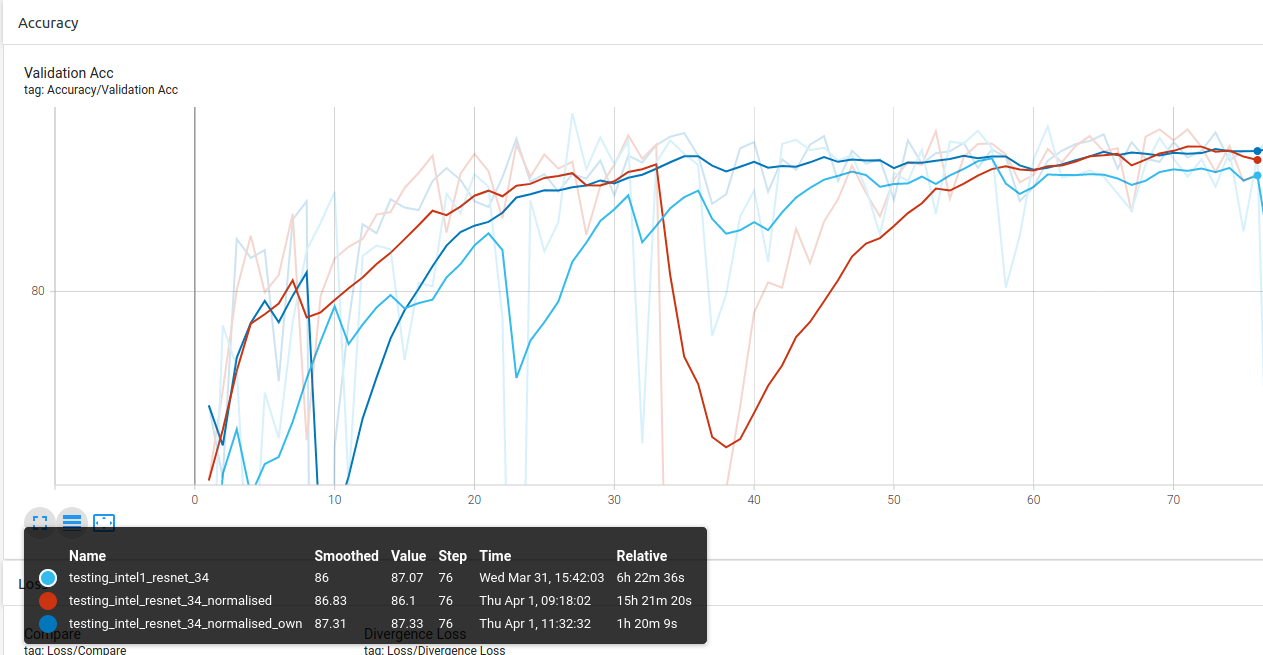
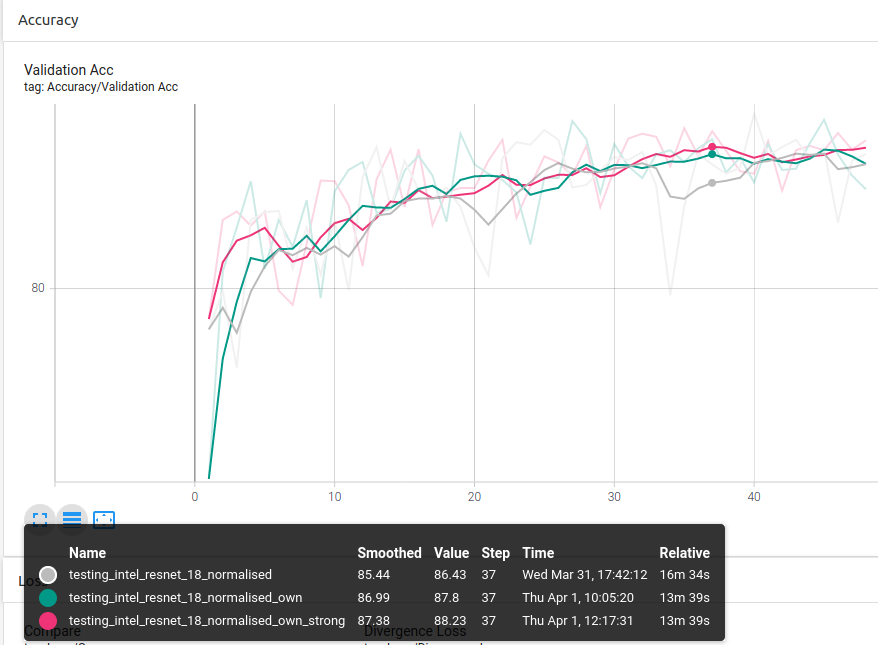
Experiment 1.2: ImageNet Custom Stats vs Own Custom Stats
Conclusion 2: Using your own dataset stats gives better result.
For further experiments into other domains like medical images and stock technical charts photos, I think it is unnecessary as it is obvious to me that your own dataset custom stats will be superior.
Personal Opinion: Just always find your own dataset mean and standard deviation, normalise accordingly. Keep this as a common practice. It only takes roughly 5 minutes to write the script and run it.
Running another test with ResNet-18, it can be observe that the Strong Method does give a little performance boost (own == weak, own_strong == strong):